Zwei bekannte Akteure vereint unter einem neuen Dach
 Illustration von Birnen und Äpfeln, public domain
Illustration von Birnen und Äpfeln, public domain
Bestimmt kennt jeder die Redewendung, man könne Birnen nicht mit Äpfeln vergleichen. Manchmal lohnt es sich aber doch genauer hinzuschauen, denn jenseits der oberflächlichen Ähnlichkeit und trotz der markanten Unterschiede verbergen sich vielleicht strukturelle Gemeinsamkeiten, die man erst auf den zweiten Blick erkennt. Wie ist das bei den beiden Agenturen ISSN und GND an der Deutschen Nationalbibliothek? Verhalten sie sich wie Äpfel und Birnen zueinander oder sind sie am Ende vielleicht wie Erdbeeren und Rosen und gehören sogar zu einer Familie? Packen Sie Ihre Forscherlupe aus und begeben Sie sich mit uns auf Erkundungstour. Und keine Angst, botanischer wird es nicht mehr.
Im Zuge der Organisationsentwicklung an der Deutschen Nationalbibliothek (DNB) sind Mitarbeitende, die zuvor in unterschiedlichen Organisationsbereichen tätig waren, nun in einem Team (M 4.2) im Referat Standardisierung und Erschließungsumgebungen (M 4) am Fachbereich Metadaten (M) zusammengefasst worden. Auch wenn die Tätigkeiten der acht Kolleg*innen relativ gleich geblieben sind, so gilt es nun die Chancen zu entdecken, die sich auf der Zusammenlegung für die Arbeit ergeben können. Nicht zuletzt, um sich tatsächlich als ein Team zu fühlen. Ein erster Schritt ist zu schauen, was ist. Ein zweiter zu analysieren, was, bei allen Unterschieden, die beiden Arbeitsfelder gemein haben. Die fachlichen Gemeinsamkeiten, genau wie das bessere Verständnis der Unterschiede, können das Zusammenwachsen des Teams fördern.
Die GND-Nutzung wird sichtbarer, aber das zu erklären braucht etwas mehr Text.
Dieser Beitrag entstand in der Zusammenarbeit mit Hubrich, Jessica und Glagla-Dietz, Stephanie .
Motivation die GND zu nutzen
Wenn es zu den Arbeitsaufgaben gehört, für die Nutzung der Gemeinsamen Normdatei (GND) zu werben, dann sollte man schon ein paar gute Argumente im Portfolio haben. Denn Normdaten zu nutzen, macht Arbeit. Das ist nicht nur der Einwand von Frau Dr. Anna Mayer in unserer fiktiven Geschichte zur Nutzung der GND im E-Learning, sondern auch von ganz realen Personen, die sich mit dem Thema beschäftigen. Die eigenen Sammlungen und Sammlungssobjekte mit Metadaten und - wo immer es möglich ist - auf Normdaten rekurrierend zu beschreiben, ist aufwändig. Im Forschungsprojekt den Text, die Bilder und andere Ausdrucksformen mit Normdaten zu annotieren, braucht Zeit. Oder Normdaten in Verwaltungsprozessen einzusetzen, um Eindeutigkeit für die bezeichneten Entitäten zu gewährleisten, das ist mit Aufwand verbunden. Dieser Aufwand lässt sich nur sehr begrenzt automatisieren. Das Recherchieren des passenden GND-Datensatzes macht Arbeit. Die Verknüpfung mit der korrekten GND-Nummer oder dem Identifikator macht Arbeit, und das Klären von Zweifeln, ob der gefundene GND-Datensatz tatsächlich zu der Aussage passt, für den man ihn verwenden will, ist aufgrund der eigenen Datenlage oft mehr als mühsam. Es ist bislang auch keine Tätigkeit, die man an einen KI-Assistenten delegieren könnte. Denn um sicher den richtigen GND-Datensatz aus über zehn Millionen Datensätzen herauspicken zu können, braucht man Expertise, Kontextwissen und last but not least auch ein wenig Glück. Schließlich besteht immer das Risiko, dass die GND die gewünschte Entität noch nicht enthält. Wie man sich dann behelfen kann, soll heute nicht unser Thema sein, Hinweise hält aber unser E-Learning mit Frau Batic bereit.
Sichtbarkeit
Eines der Argumente sich die Arbeit dennoch zu machen, neben der erzielten Eindeutigkeit in der Verwendung von Normdaten, der Arbeitseffizienz und der Kontextualisierung der getroffenen Aussage durch die Wahl der GND-Entität, ist die verbesserte Sichtbarkeit der eigenen Daten. Auf unserer Website schreiben wir zur Sichtbarkeit:
“Denn mit Normdaten steigt die Sichtbarkeit der eigenen Daten im Netz. Ein wachsendes Angebot an Plattformen wie z. B. Wikipedia, die Deutsche Digitale Bibliothek, das Archivportal D, die Nationalbibliografie, die Verbundkataloge und viele weitere nutzen die GND, um ihre Daten durch Verlinkungen sichtbarer zu machen. (…) Alle Daten, die an den Normdatensatz zu Clara Schumann geknüpft sind, vom Wikipedia-Eintrag, ihren Werken und deren Interpretationen, über Bilder und Artikel zu Clara Schumann bis hin zu den von ihr bevorzugten Instrumenten, bilden einen Einstieg, über den man zu weiteren Datensätzen kommen kann. Derart vernetzt schaffen Normdaten deutlich mehr Einstiege als etwa die museumseigene Webseite allein.”
In den hier verlinkten Folien haben wir die zentralen Vorteile der Nutzung der GND kurz zusammengefasst.
![]()
Sichtbar werden
Nutzung der GND durch Partner
Die jetzt produktiv genommenen Neuerungen betreffen jede GND-Entität und sind über die rechte Navigationsleiste aus jeder anderen Sicht erreichbar. In der Navigationsleiste gibt es jetzt ein neues Icon “Partnernetzwerk”, das alle uns bekannten Aggregationen von externen GND-Nutzungen anzeigt. Voraussetzung ist jedoch für die Anzeige im Explorer, dass es zu jedem GND-Datensatz einen Eintrag gibt, selbst wenn dieser einstweilen noch keine Verknüpfung aufweist. Daher können wir zum Beispiel nicht einen Dienst wie HAGRID der Heidelberger Akademie der Wissenschaften automatisch auswerten. Hier wird nur ein Bruchteil der GND-IDs nachgenutzt. Wir können eine entsprechende Auswertung händisch nicht leisten und wollen aber aus Gründen der Verlässlichkeit “tote” Links vermeiden. Der BEACON-Aggregator der LMU hält jedoch genau dieses Kriterium ein. Selbst in dem Fall, dass zu einer GND-Entität kein Eintrag in einer BEACON-Datei existiert, wird eine Verbindung hergestellt, nur dass dort dann kein Eintrag vorliegt (Beispiel). Durch die über die Verknüpfung einfache Weiterverfolgung der Nutzung eines GND-Datensatzes in ganz unterschiedlichen Zusammenhängen und Sammlungen kann der Nutzende des GND Explorers relativ bequem durch Verlinkung all die Ressourcen und Kontexte aufspüren, die mit einer bestimmten GND-Entität verknüpft sind. Der Identifikator zu Friedrich Schiller beispielsweise wird in fast 150 BEACON-Dateien geführt. Diese Art von multipler und dichter Vernetzung findet dann auch ihren Niederschlag in den Ergebnissen der konventionellen Suchmaschinen des Internets und erhöht damit die Sichtbarkeit der eigenen Daten. Weitere Nutzungen werden ebenfalls angezeigt. Gehen Sie auf Entdeckungsreise! (Abbildung 1)
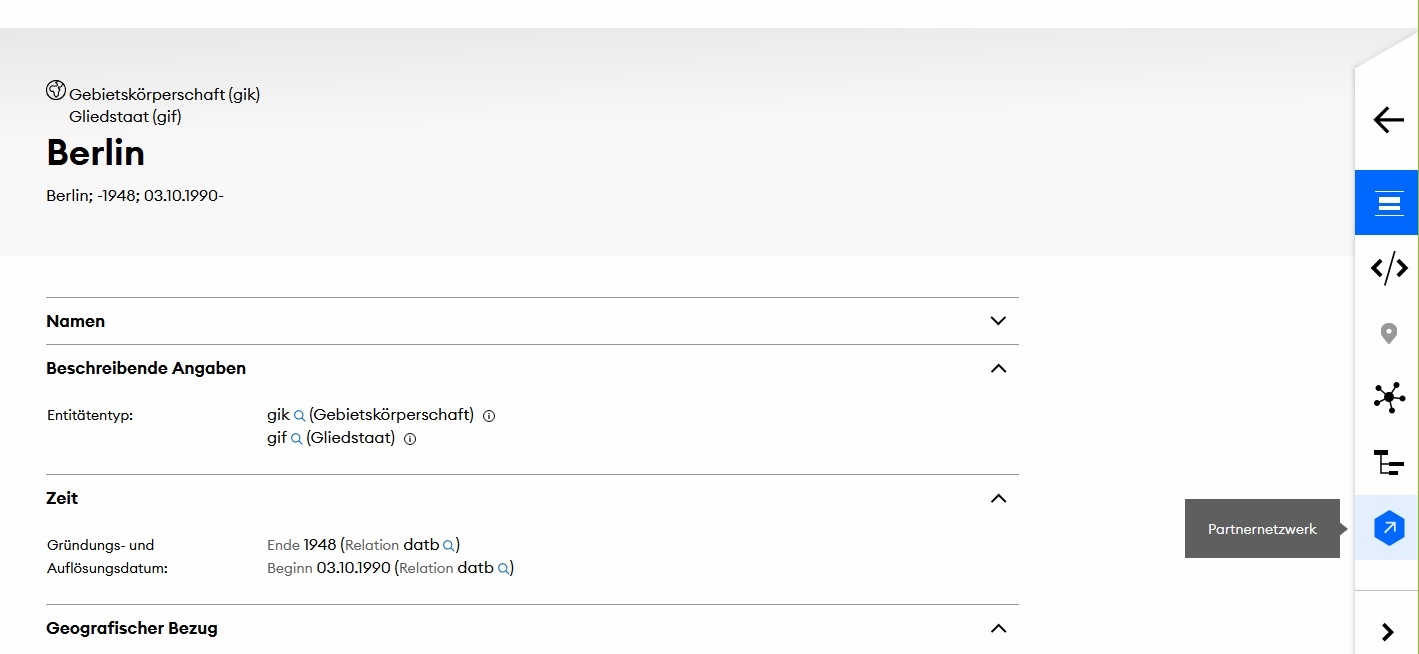
Abbildung 1 GND Faktenblatt Berlin (screenshot) Das Feature Partnernetzwerk ist rechts in der Navigationsleiste markiert.
GNDplus-Datensätze im GND Explorer
Manch einer hat es schon vernommen, derzeit entwickeln wir im Ausbau der integrativen Infrastruktur der GND einen partizipativen Datenraum: GNDplus. Künftig soll es möglich sein, hier kollaborativ an neuen GND-Datensätzen zu arbeiten, Korrekturen und Anreicherungen zu bestehenden Datensätzen vorzunehmen, die dann nach Übernahme der langfristigen Verantwortung durch eine GND-Agentur für die dauerhafte Pflege dieser Datensätze in das Produktivsystem der GND transferiert werden. Doch schon vorher bekommt jeder GNDplus-Datensatz einen Identifikator, eine PID, die dauerhaft auf diesen Datensatz verweist. Diese GNDplus-ID wird auch im GND Explorer angezeigt (Abbildung 2). Wir haben jetzt zunächst Testdaten für den partizipativen Datenraum GNDplus generiert. Damit wollen wir zeigen, wie die GNDplus Entitäten im GND Explorer dargestellt werden. Der Gedanke dahinter ist natürlich, offene Fragen zu beantworten. Uns ist es wichtig, Bedenken zu zerstreuen, die GND würde nun mit unvollständigen Datensätzen geflutet. Zugleich möchten wir Initiativen, Forschungsprojekte und andere Communities ermutigen, die für sich prüfen, ob sich der Aufwand, den partizipativen Datenraum GNDplus zu nutzen, lohnt. Gerade im Sinne der Sichtbarkeit und der Verfügbarkeit der persistenten IDs.
Abbildung 2 Das Fakentblatt für eine GNDplus Entität im Explorer (Screenshot)
Die Anzeige der GNDplus-Datensätze im GND-Explorer kann im Filter der Trefferliste ausgewählt werden. Ist die Anzeige ausgewählt, findet man die Datensätze als Entitätentyp “GNDplus” in der facettierten Suche und erhält eine Liste der Einträge. Diese Liste ist momentan noch überschaubar, nur einige wenige hundert Einträge, aber sie veranschaulichen das Grundsätzliche. Ein GNDplus-Datensatz wird durch ein invertiertes Icon kategorisiert (Abbildung 3). Während eine Sammlung im Produktivsystem der GND ein weißes Symbol für ein Textblatt in einem vollen violetten Punkt kennzeichnet, wird die GNDplus-Entität einer Sammlung mit einem weißen Punkt mit einem violetten Symbol markiert.
Wissen kompakt
Zum Schluss möchte ich Ihre Aufmerksamkeit auf ein kleines Symbol in der rechten Navigationsleiste des GND Explorers lenken. Vielleicht haben Sie es auch schon gesehen: </>. Wenn Sie diesen Menüpunkt auswählen, erhalten Sie eine Kompaktansicht des Faktenblattes nach dem Bedarf Nutzender der Pica-Formate in Bibliotheken. Die vorliegenden Daten zu einer Entität erscheinen auf die wesentlichen Merkmale reduziert: rank und schlank. So wie es manche, nicht nur in Bibliotheken bevorzugen.
Persönlich freue ich mich, dass wir mit dem GND Explorer 2.2 nicht nur ein Angebot machen, das mit seinen Visualisierungen viele Nutzende anspricht und sie motiviert, nach GND-Entitäten zu recherchieren, um sie für die eigene Arbeit nachzunutzen. Arbeit soll ja auch Freude bereiten. Sondern vor allem freue ich mich, dass das Entwicklerteam rund um meine Kolleginnen Jessica Hubrich und Stephanie Glagla-Dietz nicht müde wird, mit den oft geringen Mitteln, die uns zur Verfügung stehen, aktuelle Bedarfe aus dem Kreis der Nutzenden aufzugreifen und in neuen Versionen der Anwendung umzusetzen. Freuen Sie sich mit mir über die Version 2.2 des GND Explorers.
Kleiner Nachsatz
Es ist eine ironische Wendung, dass gerade die Qualität und Zuverlässigkeit der GND-Normdaten sowie ihre Maschinenlesbarkeit diese besonders attraktiv für Netz-Crawler, Bots und KI-Dienste macht. Deren Anfragen bringen derzeit unsere Server an ihre Kapazitätsgrenzen. Wir arbeiten an einer Lösung und bitten derweil um Nachsicht, wenn der Service nicht in jedem Moment ungehindert zur Verfügung steht.
Abbildung 3 Netzwerkansicht eines GNDplus Eintrages mit dem invertierten Icon für Sammlungen. (screenshot)
Ein Playbook zum Workshop “Demokraten und Daten” im Rahmen des Hessischen Bibliothekstages 2026
Sehr oft, wenn ich einen Blogpost schreibe, steht die Gemeinsame Normdatei (GND) im Fokus des Beitrages. Das ist auf dem GND-Blog naheliegend. Doch heute möchte ich ein Thema in den Mittelpunkt stellen, das uns alle betrifft, egal, ob wir tagtäglich mit Normdaten zu tun haben oder diese nur aus dem Lexikon kennen: Unsere demokratische Gesellschaft. Nicht nur weil in diesem Jahr viele Landtagswahltermine anstehen, kann man derzeit viel über Demokratie, Demokratiemüdigkeit, Demokratiegefährdung und Demokratieresilienz hören oder lesen. Es herrscht zurzeit mehr als nur ein Unbehagen. Die Zivilgesellschaft kommt in Bewegung. Verbände, Gewerkschaften, NGOs, Gremien der Wissenschaft und Kultur, sie alle reagieren auf die zunehmende Polarisierung des gesellschaftlichen Diskurses, auf das Erstarken demokratiefeindlicher Parteien und auf die endemische Ausbildung von Misstrauensgemeinschaften. In diesem Kontext steht die Veröffentlichung sowohl der aktualisierten GND-Leitlinien im Januar als auch das Positionspapier des Hessischen Bibliotheksverbundes “Demokratie braucht Bibliotheken” vom 11. Mai auf dem hessischen Bibliothekstag in Gießen. Alle eint das Gefühl, dass es mehr braucht als das stille Vertrauen in unsere demokratischen Institutionen, sowie die Einsicht, dass wir alle Teil dieser demokratischen Institutionen sind und wir daher selbst aktiv werden müssen, wenn uns die liberale, auf dem Grundgesetz ruhende Demokratie als sicherer Rahmen für unsere offene Gesellschaft etwas bedeutet.
Vor diesem Hintergrund haben Jakob Frohmann von der Universitätsbibliothek Frankfurt und ich unterstützt durch die Organisatoren des hessischen Bibliothekstages, dbv Hessen und der vdb Hessen, in Gießen einen Workshop für Mitarbeitende in Bibliotheken mit dem Titel “Demokraten und Daten” durchgeführt. Da wir glauben, dass man das Konzept gut als Playbook für ähnliche Workshops im eigenen Haus nutzen kann, möchte ich es kurz vorstellen.
Das Konzept
Wir haben uns für eine induktive Methode entschieden, bestehend aus Einführung, Beispiel, Gruppenarbeit und Ergebnissicherung (Abbildung 1).
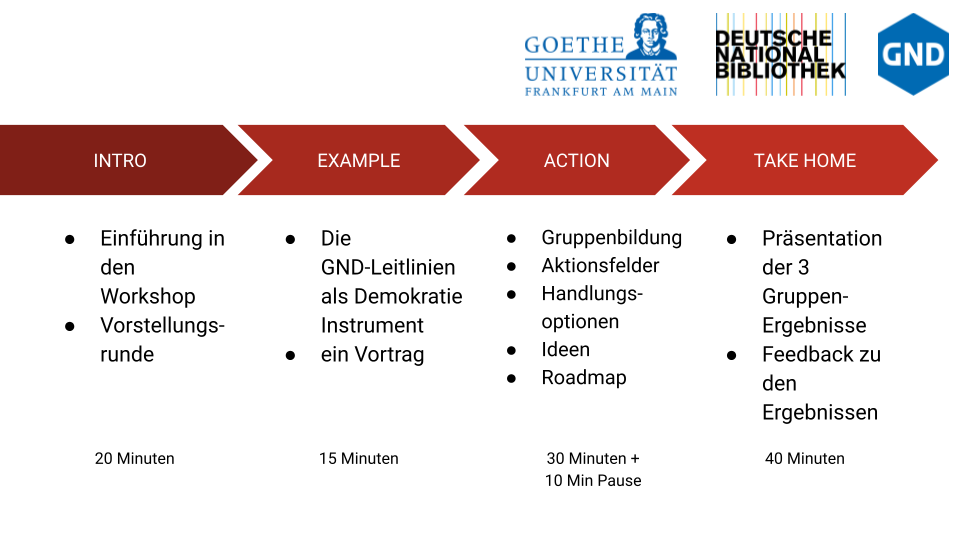
Abbildung 1: Das Zeitschema des Workshops
Dabei diente uns die Arbeit an der Aktualisierung der GND-Leitlinien als Beispiel. Eine Lehre in dieser Arbeit war es, dass es nicht immer die schnell umzusetzende Aktion sein muss, sondern dass es wichtiger ist, den Diskurs über die Maßnahme breit zu führen und Mitstreiter*innen zu gewinnen, die einem im Gang durch die Ebenen der Umsetzung den Rücken stärken, auch wenn das Zeit kostet. Im dritten Teil haben wir die Teilnehmenden eingeladen, eigene Ideen zu entwickeln. Um es den Teilnehmenden einfacher zu machen, selbst Ideen zu skizzieren, was sie zur Demokratieresilienz in ihrer Einrichtung in den Blick nehmen könnten, haben wir drei Aktionsfelder definiert. (Abbildung 2)
Im ersten Aktionsfeld nehmen wir die Daten der Bibliothek in den Fokus. Das können Katalog- oder Forschungsdaten sein, und wie wir diese vor aggressiven Manipulationen schützen können. Jüngstes Beispiel sind die wiederholten Manipulationen der “Bibliothek des Konservatismus” am Katalog des GBV-Bibliotheksverbundes, die nun per Gerichtsurteil unterbunden werden können. Aber ebenso Digitalisate aus den Sammlungsbeständen der Bibliothek. Sei es, dass man überlegt, welche Medien bevorzugt zur Demokratiebildung digitalisiert werden sollen. Oder untersucht, ob und wie Digitalisate und ihre Inhalte künftig vor Missbrauch geschützt werden müssen.
Das zweite Aktionsfeld wirft den Fokus auf die Daten der Nutzenden. Was können wir tun, um deren Daten vor Missbrauch zu schützen, wie können wir sie besser über Gefährdungspotentiale informieren? Es geht um Datenschutz, Ansprache, Datenspuren und Fragen der Integration und Inklusion.
Im dritten und letzten Aktionsfeld steht die Bibliothek selbst im Zentrum. Am digitalen Arbeitsplatz entscheidet sich die Programmgestaltung, bestimmen unterschiedliche Policies des Hauses die Arbeitsweise der Mitarbeitenden, sei es hinsichtlich der Leseförderung, oder der Auswahl der Software, KI-Anwendungen oder Cloud-Services.
Die Teilnehmenden konnten nun frei wählen, in welchem Aktionsfeld sie ihre Handlungsoptionen identifizieren wollten. Sie entwickelten erste Ideen, die jeweils kurz vorgestellt wurden. Gemeinsam haben wir dann im dritten und vierten Teil des Workshop eine erste Roadmapskizze zu der Idee erarbeitet, die uns allen am spannendsten erschien.

Abbildung 2: Die Aktionsfelder des Workshops
aus Anlass des GND-Forums Humanities@NFDI am 23. und 24. Juno in Göttingen
Am 23. und 24. Juni 2026 veranstaltet das Kleeblatt der NFDI-Konsortien mit der GND-Zentrale ein gemeinsames GND-Forum zum ersten Mal vor Ort in Göttingen. Viele Leser*innen werden sich an das online GND-Forum NFDI, FID & Co im Dezember 2024 noch erinnern. Wir erwarten gut 80 Personen zu diesem Arbeitstreffen rund um die Gemeinsame Normdatei (GND). Das Kleeblatt, das sind die vier geisteswissenschaftlichen Konsortien NFDI4Culture, NFDI4Memory, NFDI4Objects und Text+, die zusammen das Gros der Geisteswissenschaften abdecken und zugleich auch alle GLAM-Sparten ansprechen. Ziel der NFDI insgesamt ist es, eine nationale Infrastruktur für Forschungs-, Sammlungs- und Metadaten aufzubauen, die gleichermaßen für alle Forschenden zugänglich und nutzbar ist. Doch der Weg dahin ist langwierig, voller Abenteuer, komplexer und intensiver Arbeit. Es braucht sowohl technische Angebote, aber - und wer aus der GND-Gemeinschaft würde das nicht bestätigen - natürlich auch Debatten und einen Rahmen, in dem ein konsensuales Verständnis entwickelt werden kann. Es braucht eine Organisationsstruktur, definierte Workflows, Standards und letztlich eine gemeinsame Sprache, damit das Bezeichnete auch von allen gemeint und gefunden wird. Es braucht so etwas wie eine Lingua Franca.
Vielleicht denken jetzt manche Lesende, dass das pragmatische, nicht immer kunstvolle und sich stets aus vielen Kontexten bedienende Konzept der Lingua Franca gerade das Gegenteil der geordneten, kontrollierten und regelbasierten GND ist. Das stimmt schon und dann wieder doch nicht. Denn, um miteinander handeln zu können, teilen beide Konzepte die Funktionen: Verständigung sicherstellen, Eindeutigkeit bewirken und Brücken schlagen. Auf der einen Seite zwischen Menschen, die verschiedene Sprachen sprechen, und auf der anderen Seite zwischen Ressourcen, die sich in unterschiedlichen Domänen und Kontexten befinden.
Die Eckdaten
Termin
Start: Dienstag, den 23. Juno 11:30 Uhr; Registrierung
Ende: Mittwoch, den 24. Juno 2026 12:30; Veranstaltungsende
Ort
Clubräume der Zentralmensa des Studierendenwerks der Universität Göttingen
Platz der Göttinger Sieben 4, 37073 Göttingen
Anmeldung bis 16.6.2026
Eine Anmeldung ist erforderlich. Es wird keinen Stream geben können. Die Plätze sind beschränkt. Nutzen Sie zur Anmeldung diesen Link.

Das Konzept “lingua franca”
GND ID gnd/041677455
Die ursprüngliche Bedeutung der lingua franca (Ital. – „fränkische Sprache“) bezieht sich auf eine bestimmte Pidgin-Sprache, die bis ins 19. Jahrhundert an der Süd- und Ostküste des Mittelmeers als Handels- und Verkehrssprache verwendet wurde. Sie basierte auf romanischen Sprachen, aber enthielt Elemente nicht-romanischer Sprachen, hauptsächlich des Arabischen. Heutzutage wird der Begriff lingua franca als Bezeichnung für eine Sprache verwendet, die von Sprechern verschiedener Muttersprachen als gemeinsame Verkehrssprache genutzt wird. Englisch ist heute eine klassische lingua franca.
Textquelle: Glossar ICUD Seminar
Das Göttinger Programm
Das Programm wendet sich an Forschende und Mitarbeitende in den Geisteswissenschaften, deren Fachinformationsdienste, in wissenschaftlichen Bibliotheken, Musik-, Kunst- und Museumsbibliotheken sowie in Einrichtungen des kulturellen Erbes und anderen Sammlungen jeweils mit Bezug zu den NFDI-Konsortien des Kleblatts und zur GND. Das Programmkonzept für dieses GND-Forum vor Ort in Göttingen sieht drei Teile vor. Neben den Inhalten liegt den Veranstaltern besonders die aktive Partizipation aller Forumgäste am Herzen. Das spiegeln die auf den ersten Blick eventuell ungewöhnlichen Bezeichnungen der drei Veranstaltungsteile wider. Am ersten Tag fokussieren wir die praktischen Fragen, um uns am zweiten Tag Zeit für den Austausch zum weiteren gemeinsamen Vorgehen zu nehmen.
Teil 1 Ein Parcours der Tools und Anwendungen
In den vergangenen Jahren sind in den vier Konsortien wie auch in der GND-Zentrale neue Tools, Anwendungen und Services rund um die GND entstanden. Zwölf davon stellen wir den Teilnehmenden in einem Drei-Runden-Parcours vor.
Teil 2 Der Entitätstypen Fishbowl
Die Ursprünge der GND sind tief in den Bedarfen der bibliothekarischen Erschließung verankert. Ihre Regeln basieren im Wesentlichen auf zwei bibliothekarischen Standards, der verbalen Inhaltserschließung (RSWK) und dem RDA-DACH. Durch die Öffnung der GND und dem Wunsch, weitere Anwendergemeinschaften zu integrieren, kommen neue Perspektiven auf die Entitätstypen ins Spiel. Vor allem die Konzepte für “Werke”, “allgemeine und Individualbegriffe”, “Geografika” und “Körperschaften” werden von Forschenden aus den Geisteswissenschaften und dem Kulturbereich gewissermaßen als Maßanfertigungen für Bibliotheken erlebt, während sie von Bibliothekar*innen eher als One-Size-Fits-All betrachtet werden. Im Fishbowl-Format bekommen alle Teilnehmenden die Chance, sich auszutauschen, die Sichtweise des jeweils anderen besser zu verstehen und vielleicht schon Lösungswege zu skizzieren. Vier 40 minütige Fishbowls stehen den Forumgästen offen zum Eintauchen.
Teil 3 Ein Strategie Pow Wow
Pow Wows wurden ursprünglich von indigenen Gruppen in Nordamerika abgehalten, um unterstützt durch ein geregeltes Format zu Beschlüssen zu finden, die die Gemeinschaft als Ganzes betrafen. In einem metaphorischen Sinne nutzen heute auch viele andere Communities den Begriff. Wir wollen damit andeuten, dass hier nicht Top-Down eine Marschrichtung vorgegeben werden soll. Vielmehr versuchen die Veranstalter, möglichst viele der Anwesenden in einen Dialog zu zwei zentralen Fragen einzubeziehen:
- Zwischen Minimum und Maximum: Was können GND und NFDI für ein funktionales Datenökosystem leisten?
- Wie können wir uns gegenseitig unterstützen, um unsere Vorstellungen umzusetzen?
Ausgangspunkte der Diskussion sind einerseits die Eindrücke und Ergebnisse des Vortages. Zum anderen wird Jürgen Kett (DNB) in einem pointierten Vortrag skizzieren, welche Chancen und Herausforderungen das Konzept der GND als Lingua Franca für die geisteswissenschaftlichen Konsortien und für die GND insgesamt bietet. Anschließend diskutiert ein Panel zusammen mit den Teilnehmenden die obigen Fragen sowie weitere auftauchende Aspekte.
Das vollständige Programm und den Link zur erforderlichen Anmeldung finden Sie auf der Veranstaltungsseite der GND-Website. Für diejenigen, die nicht vor Ort in Göttingen dabei sein können, werden wir im Anschluss an die Veranstaltung in diesem Blog die Ergebnisse dokumentieren.

Die Zentralmensa der Göttinger Universität ist der Veranstaltungsort des GND-Forums Humanities@NFDI
Die Veranstalter
(in alphabetischer Reihenfolge)
GND-Zentrale an der Deutschen Nationalbibliothek
Text+ an der SUB Göttingen
Alle regelmäßigen Leser*innen dieses Blog wissen inzwischen, Normdaten sind systemkritische Infrastruktur. Sie helfen ebenso zuverlässig dabei, Publikationen in Bibliothekskatalogen zum Klimawandel zu finden, wie im Archivportal D Akten, die in irgendeiner Weise mit der Stadt Ulm verknüpft sind. Das Theatermuseum in Düsseldorf verwendet die GND-Daten, Forschende im NFDI-Konsortium Text+ reichern ihre Forschungsdaten mit GND-IDs an und die Praxisregeln der DFG empfehlen ihre Nutzung. Selbst das “Halluzinieren” von Künstlicher Intelligenz in Large Language Models kann in Verbindung mit Normdaten reduziert werden. GND everywhere!
Aber wie das mit Infrastruktur so ist, oft droht dabei in Vergessenheit zu geraten, dass es engagierte, zuverlässige und versierte Menschen braucht, die tagtäglich dafür sorgen, dass aus dem Hahn sauberes Wasser kommt, die Krankenhäuser funktionieren und der Müll entsorgt wird. Das gilt auch für die Gemeinsame Normdatei (GND). Viele denken jetzt vielleicht an die fleißigen Redakteur*innen, die durchschnittlich über 700 neue Datensätze anlegen. Nicht mitgezählt ihre Korrekturen, Aufarbeitungen und Ergänzungen der über 10 Millionen Datensätze. Doch es gibt neben dieser inhaltlichen Tätigkeit noch die technische Seite der GND-Bereitstellung. Um die geht es in diesem Beitrag. Gemeinsam mit meinem Kollegen Felix Riedel wollen wir heute in den “Maschinenraum der GND” steigen und schauen, welche Arbeiten dort anfallen, die das Getriebe der GND am Laufen halten.

Im Maschinenraum der GND. Bildnachweis: Motiv mit KI (Firefly) kreiert.
Der Maschinist der GND
Wenn zum Beispiel das Expertenteam Qualität einen wiederkehrenden Fehler in den Daten korrigieren will, dann landet dieser Vorgang auf seinem Schreibtisch. In einem ersten Schritt sucht Felix Riedel zunächst in allen vorliegenden GND-Daten nach diesem Fehler. Dabei nutzt er meistens ein im Haus entwickeltes Tool (Pica rs). Mit diesem Werkzeug kann er beispielsweise all diejenigen Datensätze identifizieren, bei denen die Angabe zur GND-Systematik fehlt oder bei denen die Quellenangaben nicht hinreichend dokumentiert sind. Als Ergebnis erhält er eine Liste mal mit hundert Datensätzen, manchmal aber auch mit zigtausend Einträgen. Selbstverständlich wird weder er noch ein anderer diese Menge händisch bereinigen können. Jetzt muss Felix Riedel kreativ werden. Wie lässt sich ein kleines Skript schreiben, mit dem zuverlässig die Massenkorrektur an den identifizierten Datensätzen ausgeführt werden kann? Manchmal ist der erste Ansatz nicht gleich der richtige. Unterstützt durch entsprechende Validationsverfahren, arbeitet sich Felix Riedel Stück für Stück voran, bis schließlich der Fehler behoben ist. In den letzten Jahren hat Felix Riedel hier recht viel Erfahrung sammeln können, die er auch entsprechend dokumentiert. In den nächsten Monaten ist geplant, dass diese Dokumentation Teil der Information auf der STA-Dokumentationsplattform wird, damit mehr Menschen von Felix Riedel Erfahrung profitieren können.
Einmal Pica und zurück
Ein anderes Arbeitsfeld ist die Datenkonversion. Die DNB und andere Bibliotheken nutzen für interne Arbeiten mit der GND das Pica-Format. Da dieses Format jedoch nicht von allen Partnern in der Kooperative genutzt wird, müssen die Daten von Pica nach Marc 21 (auch nach Marc XML) und zurück konvertiert werden. Dabei achtet Felix Riedel darauf, dass bei der Konversion die Informationen möglichst vollständig übertragen werden. Die Datenkonversion läuft nicht vollautomatisch ab. Ohne Monitoring können sich Lücken oder Fehler einschleichen. Zum Beispiel kann es passieren, dass bestimmte Pflichtfelder nicht mitkonvertiert werden oder Feldeigenschaften falsch angewandt wurden, was zu Fehlermeldungen führt.
Das Nadelöhr
Sein drittes Arbeitsfeld gilt den Datenimporten. Zum Beispiel hat er den Datenimport von mehreren 10.000 Daten aus der Theaterdatenbank Ulrich in die GND begleitet. So ein Datenimport kommt bei Felix Riedel oft als MarcXML-Datei an. Die Daten konvertiert er in das Pica-Format, damit sie im Approvalsystem der GND validiert werden können. Jetzt bekommt er eine erste Liste mit Fehlermeldungen. Oft sind es drei bis vier kleine Fehler, die sich dann aber durch fast alle Daten durchziehen. Diese als Fehlertyp zu identifizieren ist meist intellektuelle Handarbeit. Leider sind es in den vielen unterschiedlichen Datenlieferungen nicht immer dieselben Fehler. Aufgrund der hohen Variabilität der von den Datengebern gelieferten Daten variieren die Fehler entsprechend. Daher gehen die Testdaten zurück an die Datengeber mit der Bitte, den Fehlertyp zu korrigieren. Wenn das geschehen ist, wird der Vorgang mit neuen Testdaten wiederholt, in der Hoffnung, dass sich keine neuen Fehler eingeschlichen haben. Erst wenn die Validierung widerspruchslos bleibt, überführt Felix Riedel die Daten in das Produktivsystem der GND. Ein Vorgang, der für alle Beteiligten manchmal zäh und nervenaufreibend ist. Ein Hinweis von Felix Riedel an die Datengeber: Die Validation springt vor allem auf Formalfehler an. Diese kann man vermeiden, wenn man die Daten, die man in die GND einbringen möchte, so regelkonform wie möglich erstellt. Dabei helfen zum einen die GND-Dokumentation und die Informationsseite zu den Validierungen im öffentlich zugänglichen Wiki der DNB.
Schließlich obliegt es Felix Riedel, die Wünsche aus dem Releaseprozess zur GND-Dokumentation in ein technisches Format zu transponieren. Etwa wenn ein neues Feld in das Datenformat eingefügt werden soll. Hierbei muss Felix Riedel die internationalen Standards und die technischen Abhängigkeiten berücksichtigen. Die eigentliche Umsetzung übernehmen dann jedoch Fachleute aus der IT-Abteilung der DNB.
Felix Riedel mag seine Arbeit. Sie ist abwechslungsreich und bietet ihm viel Gelegenheit, in der Vielfalt der Daten immer neue Lösungen für immer neu auftretende Fehler zu finden. Besonders schätzt er jedoch den direkten Austausch mit den Partnern im GND-Netzwerk. Da kann er mal den Maschinenraum verlassen.

Unter dem Motto „Mitmachen“ fand am Montag, den 16. März 2026 das nunmehr 6. GND-Forum statt. Mit bis zu 101 zugeschalteten Personen blieb die Anzahl der Teilnehmenden weitgehend stabil. Im Organisationsteam waren Kolleginnen und Kollegen der Arbeitsstelle für Standardisierung an der DNB, dem Bundesarchiv, dem Hessischen Landesarchiv, der Staatlichen Archive Bayerns, dem Geheimen Staatsarchiv Preußischer Kulturbesitz, dem Bundesarchiv, dem Landesarchiv Baden-Württemberg mit der dort angesiedelten GND-Agentur LEO-BW-Regional, dem Institut für Stadtgeschichte in Frankfurt, der Universität Hohenheim und der Technischen Universität Dortmund vertreten.
Dr. Patrick Leiske (Landesarchiv Baden-Württemberg) und Dr. des. Johannes Haslauer (Staatsarchiv Bamberg) begrüßten die Teilnehmenden, stellten den Programmablauf kurz vor und gaben organisatorische Hinweise.

Das Programm. Zum Vergrößern bitte draufklicken
1. Neuigkeiten aus dem GND Kontext
Barbara Fischer von der Deutschen Nationalbibliothek berichtete über die seit April 2025 erfolgten Neuerungen. Eine Momentaufnahme am Tag der Veranstaltung ergab eine Anzahl von inzwischen 10.239.824 Datensätzen in der GND. Auch auf der GND-Webseite gibt es einige neue Inhalte. So wurde etwa die Startseite aktualisiert, neue Partner gewonnen, die Infothek nach der Anregung des 5. GND Forum Archiv nach thematischen Zugängen neu geordnet und mit neuen Inhalten ergänzt. Auch die GND Dokumentation mit ihren Regeln zur Erfassung von GND Entitäten ist jetzt über die GND Website erreichbar. 14 neue Blogbeiträge zu diversen Aktivitäten rund um die GND wurden verfasst. Der GND-Explorer befindet sich inzwischen mit Version 2.1 im Produktivsystem. Die Vernetzung zu anderen Datenportalen wie Wikidata wurde verstärkt. Neu hinzu kam auch eine DDC-Klassifizierung. Ab April 2026 soll Version 2.2 mit einem Verzeichnis der Nutzung von GND IDs durch externe Partner (z. B. Beacon Dateien) bereitstehen. Über den GND-SPARQL-Endpoint sind die Ergebnisse der Suche auch maschinell auslesbar und nutzbar.
Für den Veranstaltungsbereich haben sich die GND-Foren als Dialogräume für Communities etabliert. Seit dem 5. GND-Forum im April 2025 haben ein Workshop der IG Archiv zum Thema Schulung (Dokumentation) sowie ein projektübergreifendes Treffen der neuen Agenturen (Dokumentation) stattgefunden. Die IG Museen hat zwei Workshops zur GND-Dokumentation ausgerichtet. Für Juni 2026 ist ein GND-Forum Humanities @NFDI geplant. Die bereits lange geplante Onlinestellung der GND-Dokumentation mit den Regeln für Akteure (Personen, Familien, Körperschaften, Konferenzen und Gebietskörperschaften) und Geografika konnte realisiert werden. Im Zuge der Verstetigungsmaßnahmen konnte die neue und überregional tätige GND-Agentur „Bauwerke“ (Deutsches Dokumentationszentrum für Kunstgeschichte, Bildarchiv Foto Marburg) in den Dauerbetrieb übergehen. Die regionale Agentur für Archive in Berlin und Brandenburg am Geheimen Staatsarchiv Preußischer Kulturbesitz (Fokus auf Personen, Körperschaften und Geografika) nahm den Pilotbetrieb auf. Etliche Fachinformationsdienste bieten Beratung und Normdaten on demand an und bilden seit kurzem eine eigene Interessengruppe. Im Ausblick wurde abschließend der neue partizipative Datenraum GNDplus vorgestellt. Es soll ein Inkubator (neue Entitäten anlegen, diskutieren und zur Aufnahme in die GND vorschlagen), ein Feedback-Dienst (Änderungsvorschläge für bestehende GND-Entitäten anlegen) und ein Anreicherungsdienst (Zusatzinformationen zu Entitäten anlegen) entstehen. In Zukunft soll auch das Thema "GND und KI" vermehrt in den Fokus genommen werden. Durch den Abgleich mit der GND soll es in generativen KI-Anwendungen weniger Gefährdung durch das "Halluzinieren" von Information geben. Ein Überblick über die wachsende GND-Community machte deutlich: Die GND wird vielfältiger, umfassender, diverser, vernetzter und damit attraktiver und resilienter für Archive, Bibliotheken, Museen, Verwaltungen und die „Künstliche Intelligenz“.
Die Folien des Vortrages. Zum Vergrößern bitte draufklicken
Einsteigen in die Normdatenarbeit in Kooperation mit einer Bibliothek
Im ersten Vortrag, unter dem Motto "Together We Create", berichtete Michael Franke-Maier von der Universitätsbibliothek der Freien Universität Berlin über die Strukturen der Normdatenarbeit innerhalb der strategischen Allianz zwischen dem Kooperativen Bibliotheksverbund Berlin-Brandenburg, der Bayerischen Staatsbibliothek und dem Bibliotheksverbund Bayern. Innerhalb der Allianz kann damit auf das Know-how von zwei großen GND-Agenturen (KOBV und BSB/BVB), drei erfahrenen GND-Verbundredaktionen (UB der FU Berlin, BSB und UB Augsburg) und mehrerer dezentraler, sehr gut vernetzter GND-Lokalredaktionen zurückgegriffen werden.
Für den Teilbestand Sacherschließung übernimmt die Verbundredaktion an der Universitätsbibliothek der FU Berlin für den gesamten KOBV die redaktionellen Arbeiten, während die Verbundredaktion der Bayerischen Staatsbibliothek für die Entitäten Personen, Geografika, Körperschaften und Konferenzen, Schriftdenkmäler und Werke mit geistigem Schöpfer für ihre Institution und den BVB zuständig ist. Die Redaktion für Sachbegriffe und anonyme Werke der Sacherschließung für BSB und BVB übernimmt die Verbundredaktion an der Universitätsbibliothek in Augsburg.
Wichtig für den Gesamtworkflow der GND-Agentur des KOBV ist die Unterscheidung zwischen Inhalts- und Formalerschließung. Während dort die Formalerschließung auch durch dezentrale Lokalredaktionen erfolgt, wird Normdatenarbeit für die Inhaltserschließung an der Universitätsbibliothek der Freien Universität zentral durchgeführt.
Neben der Neuerfassung von GND-Entitäten auf Level 1 arbeitet die GND-Verbundredaktion für die Inhaltserschließung auch in GND-Gremien mit, führt Regelwerksschulungen (RSWK) durch und berät KOBV-Teilnehmerbibliotheken bei Fragen. Dabei arbeitet sie mit den GND-Anwenderbibliotheken des KOBV, mit verschiedenen Fachinformationsdiensten (Sozial- und Kulturanthropologie an der HU Berlin, Anglo-American Culture & History an der FU Berlin und Gender an der HU Berlin) und weiteren Forschungseinrichtungen, z. B. der Baltisch Historischen Kommission, zusammen. Insgesamt wurden in den Jahren 2024 und 2025 über 700 Neuansetzungen oder Upgrades in der GND in den Entitäten Personen, Körperschaften, Konferenzen, Geografika, Werke und Sachbegriffe gemacht. Für die Zusammenarbeit mit Lokalredaktionen, den Fachinformationsdiensten und dem Projekt „Critical Library Perspectives“ wurden unterschiedliche Workflows vereinbart. Eine länger andauernde Diskussion ging z. B. der Ansetzung des Sachbegriffs „Gender“ in der GND voraus, der im Februar 2024 realisiert wurde. Weitere GND-Einträge mit Genderbezug werden überarbeitet.
In seinem Fazit stellte der Referent fest, dass Bibliotheken – abhängig von Personalkapazitäten – immer für eine Kooperation offen sind und auch unterschiedliche Formen der Zusammenarbeit möglich sind. Metadaten (und Normdaten) erweisen sich letztlich als Schlüssel für den Zugang zu Wissen (DBV-Positionspapier vom Dezember 2025). Die GND lebt von der Kooperation und entwickelt sich täglich weiter.
Die Folien des Vortrages. Zum Vergrößern bitte draufklicken
Notizen aus der Breakout Session
In der ersten Breakoutsession zum Vortrag von Michael Franke-Maier wurde deutlich, dass die Unterschiedlichkeit der erfassten Entitäten, aber auch die Workflows in den Partnereinrichtungen die Arbeit der GND-Agentur abwechslungsreich gestalten. Eine Herausforderung ist etwa auch die Anlage fiktiver – etwa literarischer – Personen als Entität, weil Personendatensätze keinen „Creator“ vorsehen. Auch lasse sich die Realität nicht immer normieren – beispielsweise ist es bei nordamerikanischen Reservaten nicht leicht zu entscheiden, ob diese als Geografika oder ggf. sogar – abhängig von deren Organisationsgrad – als eine Gebietskörperschaft in der GND erfasst werden. In der Community der Critical Libraries werden auch diskriminierende Begriffe diskutiert. Die Ansetzung von Normdaten muss auch insgesamt durch Diskussionen mit anderen (Fach-) Communities, etwa Archiven, weiterentwickelt werden. So gibt es etwa eine von Bibliotheken und Archiven gemeinsam geführte Diskussion zur Weiterentwicklung der Ansetzung von Ghettos zur Zeit des Nationalsozialismus, jedoch ohne Blaupause oder Erfahrung der Zusammenarbeit mit den bisher unterschiedlichen Erschließungskulturen. Es stellte sich auch die Frage nach Möglichkeiten der Normierung und Standardisierung in der archivischen Erschließung, der besonders nachdrücklich von der technischen Seite gefordert wird.
Kultur.Gut.Normieren mit den GND-Webformularen
Im zweiten Vortrag stellte Jens M. Lill vom Bibliotheksservicezentrum Konstanz die von der DNB bereitgestellten GND-Webformulare zur Eingabe von Personen und Körperschaften vor. Durch ihre einfache, bequeme und direkte Nutzbarkeit bieten sie einen niederschwelligen Zugang zur produktiven Neuansetzung von GND-Datensätzen. Sie zeichnen sich durch ein einfaches Design und intuitive Bedienbarkeit ohne Regelwerkskenntnisse aus, was sie für nicht-bibliothekarische Anwender*innen leicht nutzbar macht. Die abgespeicherten Eingaben landen unmittelbar in der GND und können sofort nachgenutzt werden. Gleichzeitig findet ein einfacher Dublettencheck statt. Möglich sind sowohl eine Neueingabe als auch eine Ergänzung von bereits vorhandenen Datensätzen. Nicht möglich ist allerdings die Zusammenführung von Dubletten, die dann in der redaktionellen Bearbeitung jeweils miteinander verlinkt werden. Hinweise oder Korrekturwünsche können über eine Korrekturanfrage bei der DNB hinterlegt oder bei der zuständigen GND-Agentur eingebracht werden. Voraussetzung für die Nutzung der GND-Webformulare ist die Registrierung bei der DNB fürs Log-in, ein sog. ISIL (International Standard Identifier for Libraries and Related Organizations) und die redaktionelle Betreuung durch eine GND-Agentur oder Bibliothek. Die GND-Agentur LEO-BW-Regional bietet außerdem regelmäßig Schulungen an. Inzwischen ist auch eine Agenturhandreichung für das Webformular vorhanden. Wichtig für die Eingabe neuer Datensätze sind auch die Beachtung der Eignungskriterien, ein berechtigter Bedarf, eine freie CC0-Lizenz, verlässliche Quellenangaben und Regelkonformität.
In seinem Fazit betonte der Referent die durchweg positiven Erfahrungswerte mit den bislang ca. 5500 neu eingebrachten Datensätzen. Zu den bisher vorhandenen Webformularen für Personen und Körperschaften/Organisationen soll noch 2026 ein Webformular für Gebietskörperschaften in dem Entitätstyp Geografika hinzukommen.
Die Folien des Vortrages. Zum Vergrößern bitte draufklicken
Zusammenfassung der Breakout Session
In der zweiten Breakoutsession führte Jens M. Lill die Webformulare für Personen und Körperschaften anhand von Produktivdatensätzen vor (bzw. wurden auch neue Personendatensätze angelegt) und beantwortete Rückfragen aus dem Kreis der Teilnehmenden. Seitens der GND-Agentur LEO-BW-Regional besteht ein Angebot von 2 Schulungen im Jahr für Kultureinrichtungen aus Baden-Württemberg. Die nächste wird voraussichtlich im November/Dezember 2026 stattfinden.
Außerdem wurde die Bedeutung der Zusammenarbeit von Archiven und Bibliotheken beleuchtet und folgende Erfahrungen geäußert: Die gemeinsame Arbeit der GND-Agentur wird durch die Zusammenarbeit besonders abwechslungsreich, Neuerungen und Weiterentwicklungen in der Normdaten-Arbeit werden angestoßen, die eigene Arbeitsweise bereichert. Als aktuelles Beispiel dafür kann die Arbeit an der Ansetzung von Normdaten für NS-Ghettos dienen. Der Druck zur Standardisierung, der durch die technische Bedingtheit entsteht, wird auf archivischer Seite mitunter als Herausforderung wahrgenommen und zeigt unterschiedliche Erschließungstraditionen auf.
Data Literacy und GND-Referenzierung – praktische Erfahrungen aus dem Staatsarchiv Bamberg
Der dritte Vortrag "Data-Literacy und GND-Referenzierung am Staatsarchiv Bamberg " von Maximilian Stimpert war ein Fortsetzungsbericht basierend auf dem Projekt „Hands-on Normdaten!“, vom dem bereits beim 4. GND-Forum im September 2024 berichtet wurde. Data Literacy, d. h. Datenkompetenz (Daten lesen, erheben und verstehen) stellt ein zentrales Gebiet für Archivar*innen dar. Einzelne Themenfelder sind die Erschließung, die Bereitstellung von Informationen in Findmitteln und die Normdatenarbeit als Tool zur Sicherung der Datenqualität. Als Praxisbeispiel wurde die Einbindung von Personennormdaten ins AFIS aufgezeigt. Dabei kamen die Entitäten Ortsnamen, Personennamen und Sachbegriffe zum Einsatz. Im Zuge des Projekts gab hatte es eine Zusammenarbeit mit der Bayerischen Staatsbibliothek und der GND-Agentur Bayerische Staatsbibliothek/Bibliotheksverbund Bayern gegeben. Die in den Erschließungsdaten vorhandenen Metadaten über Personen – beispielweise Angaben über Geschlecht, Beruf, Wirkungsort und Wirkungsdatum – stellen in der Regel eine gute Grundlage dar, um neue GND-Datensätze anzulegen. Als Beispiel führte der Referent den Wirkungskreis eines Bamberger Domkanonikers und der mit ihm verbundenen Personen, Orte und Körperschaften aus. Bei einer Bearbeitungsdauer von vier Wochen konnten insgesamt zwei Archivbestände, 685 Verzeichnungseinheiten und 761 Entitäten bearbeitet sowie 324 GND-Datensätze eingebunden werden. In seinem Fazit stellte er kurz und knapp fest: Mitmachen lohnt sich!
Die Folien des Vortrages. Zum Vergrößern bitte draufklicken
Angeregte Diskussion in der Breakout Session
Die dritte Breakoutsession widmete sich dem Impulsvortrag von Maximilian Stimpert. Es wurde über die Frage gesprochen, wie man am besten die Metadaten vorhält, die zur Anlage neuer benötigter Datensätze in der GND dienen können. Herr Stimpert berichtete, dass dies beim Staatsarchiv Bamberg bislang parallel in einer Excel-Tabelle in entsprechend strukturierter Form erfolge. Herr Haslauer wies auf den Beispielworkflow für den Import von Personendatensätzen in die GND hin, den das Staatsarchiv Bamberg zusammen mit den GND-Agenturen BSB/BVB und Text+ (SUB Göttingen) zur Nachnutzung entwickelt hat (siehe Beschreibung und Links in der IG-Handreichung "Tipps & Tricks für die erfolgreiche Nutzung von Tools zum Einsatz der GND im Archiv", Abschnitt IV 3).
Der Erfahrungsaustausch über den GND-Abgleich anhand der lobid-gnd-Schnittstelle in OpenRefine sowie über die ins AFIS implementierte SRU-Schnittstelle zeigte, dass die automatisierte Vorgehensweise zwar bei bestimmten Szenarien vorteilhaft genutzt werden kann (v.a. bei vielen gleichen Entitäten in den Datensätzen), darüber hinaus aber an Grenzen stoße, sodass immer noch in größerem Maß intellektuelle, händische Arbeiten erforderlich sind. Daher gingen mit dieser Qualitätssicherung nicht unerhebliche Aufwände einher. Je eindeutiger bzw. besser strukturiert die Daten jedoch vorliegen, desto besser funktioniere der Abgleich. Betont wurde die Bedeutsamkeit, auch Körperschaften mit der GND zu verknüpfen, da sich hiermit Bestands- bzw. Provenienzbildner abbilden lassen. Ob die empfehlenswerte Verknüpfung von GND-IDs auf Bestandsebene möglich ist, ist jedoch vom eingesetzten AFIS abhängig. Grundsätzlich ist beispielsweise die Möglichkeit zur Einbindung von Körperschafts-GND-Datensätzen in die VZEs bei den Staatlichen Archiven Bayerns in Planung.
Festgehalten wurde auch, dass eine Weiterentwicklung der AFIS-Systeme vor allem in zwei Richtungen wünschenswert wäre. Dies beziehe sich einerseits auf möglichst flexible und zielführende Abgleichfunktionen (Abgleich über mehrere Felder), so dass ein aufwändiger Ex- und Import der Daten zur Bearbeitung mit Tools außerhalb des AFIS überflüssig werde. Zum anderen gehe es um die Bereitstellung von Export-Workflows, mit denen Metadaten über die Entitäten beispielsweise in einem Thesaurus strukturiert erfasst und anschließend automatisiert im MARC-Format der GND zugeführt werden können.
Unstrittig waren die Aufwände, die mit der Aufnahme von Entitäten einhergehen, etwa mit der Erfassung mehrerer Personen (z.B. Korrespondenzpartnern) je Verzeichnungseinheit. Betont wurde aber auch, dass die GND-Referenzierung gerade im Archivportal-d die Aufmerksamkeit und die Reichweite steigere. Im Hinblick auf die strategische Ausrichtung von Archiven trage die GND-Nutzung bei der Erschließung zu erhöhter Sichtbarkeit, Auffindbarkeit und Interoperabilität der Daten bei sowie auch zu deren Qualität und zur automatisierten Nachnutzbarkeit etwa durch die Digital Humanities, die auf qualitativ hochwertige Daten angewiesen seien. Datenbereinigung und Homogenisierung seien daher wichtige Arbeitsziele für die Archive. Inwiefern eine KI-gestützte Entitätenerkennung und Verlinkung mit der GND in der Zukunft zuverlässig möglich sein wird, bleibt abzuwarten.
Die Folien des Vortrages. Zum Vergrößern bitte draufklicken
Notizen aus der Breakout Session
Die vierte Breakoutsession nutzten viele der Teilnehmenden um sich über den künftigen Dienst GNDplus tiefergehend zu informieren. Die Referentin Sarah Hartmann betonte nochmals, dass Ergänzungen und neu vorgeschlagene Entitäten in GNDplus zwar in einer eigenen Datenbank liegen, aber über den GND Explorer angezeigt werden. Es wurde angeregt, dass die Daten aus GNDPlus auch in LOBID eingebunden werden sollten. Vorgeschlagene Entitäten oder Korrekturen können, wenn sie den Regeln entsprechen und die technischen Möglichkeiten vorliegen, später in die GND übernommen werden. Nicht in allen Fällen wird dies allerdings möglich sein, z. B. weil das Format der GND dies nicht zulässt. Die Übernahme in die GND soll über ein redaktionelles Verfahren gesteuert werden. Beim Anlegen eines neuen Datensatzes in GNDplus wird sofort ein Persistent Identifier vergeben, der auch direkt zurück geliefert wird. Identifier von Entitäten, die nicht mehr gültig sind (z.B. bei Umlenkungen oder Zusammenlegung von Dubletten), bleiben erhalten bzw. es wird dokumentiert, dass diese nicht mehr verwendet werden. Weitere Anwendungsmöglichkeiten für GNDplus können etwa akademische Jahresfeiern als Veranstaltungen oder aber generell als Sachbegriff sein. Auch im Bereich GNDPlus bedarf es einer Registrierung und der Kooperation mit einer Redaktion/Agentur, die langfristig die Pflege der Daten gewährleistet. Sie entscheidet auch über die Übernahme eines Datensatzes. In GNDplus kann auch kooperativ an einem Datensatz gearbeitet werden. Dies ist ein Vorteil, wenn in einer Institution nicht genügend Merkmale (Metadaten zu der jeweiligen Entität) für einen vollständigen Datensatz vorliegen. Es könnte dann z. B. eine andere Institution weitere Merkmale (Metadaten) ergänzen. Historische Geokoordinaten können auch, entsprechend gekennzeichnet, ergänzt werden.
In GNDplus wird kein allumfassende neues Datenmodell für alle community-spezifischen Metadaten verwendet, sondern es werden für bestimmte Anwendungskontexte konkrete Lösungen für spezifische Bedarfe, z. B. für ergänzende Merkmale, die nicht in der GND vorgehalten werden können, gefunden.

Die Infografik zeigt das Aufgabenspektrum einer GND-Agentur. Sie diente als Hintergrund für die Podiumsdiskussion. Bildnachweis: Kett (DNB), 2024, CC BY SA. Zum Vergrößern bitte draufklicken
4. Podiumsdiskussion „Wir sind eine Agentur“- Anforderungen und Erfahrungen
Unter der Moderation von Frau Dr. Mirjam Sprau berichteten mehrere für unterschiedliche Agenturen tätige Personen über ihre Erfahrungen. Es wurde eine Infografik (nebenstehend) mit den verschiedenen Agenturaufgaben gezeigt und daraus folgende Leitfragen generiert: Welche Agenturaufgaben machen am meisten Spaß? Was trägt die Agentur? Wo ist sie angesiedelt? Wie lange besteht sie schon? Was sind Arbeitsschwerpunkte, Ziele oder mögliche künftige Arbeitsbereiche?
Dr. Patrick Leiske und Jens Lill von der Agentur LEO-BW-Regional hoben dabei die Öffentlichkeits- und Communityarbeit, den Austausch, die Redaktionsarbeit und die Schulungen als wichtige Aufgaben hervor, die auch einen gewissen Spaßfaktor beinhalten können. Die in Kooperation betriebene Agentur ist an das vom Landesarchiv Baden-Württemberg verantwortete Landeskunde-Portal LEO-BW angedockt. Die Protoagentur MusIS war am Bibliotheksservice-Zentrum Baden-Württemberg in Form einer Fachredaktion für Museen und Sammlungen bereits vorhanden. In der Einstiegsphase ist ein bibliothekarischer Tandempartner auf jeden Fall von Vorteil. Für die Finanzierung stünden leider nur Bordmittel zur Verfügung, so dass die Agentur trotz ihrer Etablierung seit etwas mehr als fünf Jahren nach wie vor in Nebenarbeit als Zwei-Mann-Betrieb mit redaktioneller Unterstützung durch zwei weitere Personen betrieben werden muss. Der Arbeitsalltag ist geprägt von der Redaktionsarbeit als Tagesgeschäft, der Mitorganisation der GND-Foren, der Mitarbeit im GND-Ausschuss, der Regelwerksarbeit (z. B. für NS-Ghettos) und automatisierten GND-Einspielungen für das Wiedergutmachungsprojekt. Als künftige Aufgaben wären ein informeller Austausch zwischen den einzelnen Agenturen und regelmäßige Lobbyarbeit denkbar.
Gudrun Hoinkis von der GND-Agentur Berlin-Brandenburg benannte die Redaktion von Personennormdaten im bibliothekarischen Bereich, aber auch anderer Entitäten und die Arbeit mit verschiedenen Projektpartnern als diejenigen Aufgaben, die ihr am meisten Freude bereiten. Auch ihre Agentur wird nicht in Vollzeit betreut. Es ist vielmehr ein Stellenanteil für die Arbeit in der Agentur reserviert. Sie wurde im Jahr 2024 gegründet und hatte anfangs vier, jetzt nur noch drei Mitarbeitende. Es wird derzeit mit drei Archiven zusammengearbeitet, die Dateneingabe erfolgt dort über die GND-Webformulare. Außerdem werden Redaktionsarbeiten geleistet. Häufigste Aufgaben sind Redaktion, Qualitätssicherung und die Abgleichung eingereichter Listen mit OpenRefine. Für die Zukunft erhofft sie sich mehr Körperschaften für die GND, für die bisher wenig Bedarfe gemeldet wurden und mehr Communityarbeit.
Abschließend berichtete Dr. Anne Purschwitz von der geplanten GND-Agentur der Geschichtswissenschaften. Grundlage ist das Projekt NFDI4Memory, dessen erste Förderungsphase von fünf Jahren zur Hälfte geschafft ist. Ihre Agentur befindet sich derzeit in Gründung. Es erfolgt bereits jetzt Beratung und Support kleiner Projekte, aber auch Aufklärungsarbeit. Derzeit sind (in Teilzeit) fünf Kolleg*innen und ein Bibliothekar für Schulungen beschäftigt, wünschenswert seien allerdings zwei dauerhafte Personalstellen. Deren Finanzierung ist bisher aber ungeklärt. Mehr Klarheit soll die Ermittlung von GND-Bedarfen bei Historiker*innen, in Archiven, Citizen Sciences etc. bringen. Ziele der Agentur sind die bessere Verknüpfung historischer Ressourcen, eine gemeinsame Nutzung und Pflege von Normdaten, sowie die Priorisierung der Ansetzungen. Bisher sei die Redaktionsarbeit aber noch nicht produktiv. Es besteht vielmehr eine Sammlung von Informationen zu künftigen GND-Datensätzen. Wichtig für die Zukunft wäre daher ein Überblick, wer alles in GND-Projekten arbeitet, eine Verknüpfung von Informationen, Sammlung und Abgleich lebender Forschungsdaten und ein gegenseitiges Sichtbarmachen von Projekten. Eine Zusammenarbeit mit den Arolsen Archives und dem Buchenwald-Projekt soll den Zugang zu Ressourcen erleichtern.
Abschließend betonte Dr. Mirjam Sprau, dass Agenturen nicht die Rollen von Gatekeepern, sondern von Vermittlern hätten. Außerdem müssen sich die technischen Voraussetzungen für die Arbeit mit der GND verbessern, wobei auch die Softwareanbieter gefordert seien. Hierfür müsse auch die Kommunikation zwischen Anwendern und Entwicklern verbessert werden. Außerdem rief sie zur Kontaktaufnahme mit den Agenturen auf.
5. Resümee und Ausblick
In ihrem Schlussstatement betonte Dr. Stephanie Marra von der TU Dortmund, dass die Zusammenarbeit in der GND-Community zwar komplex, aber wirkungsvoll sei. Sie regte die Weiterentwicklung hilfreicher Werkzeuge wie der Webformulare, des GND-Explorers oder GNDplus an und wünscht sich weiterhin ein kontinuierliches Wachstum der GND-Community. Immer wieder entstehen neue Fachinformationsdienste und neue Entitäten. Anlässlich des 6. GND-Forums wurde nun erstmalig eine Podiumsdiskussion als vielversprechendes neues Format durchgeführt. Sie rief Neueinsteiger*innen auf, künftig mitzumachen und persönliche Belange einzubringen und wies abschließend auf kommende Veranstaltungen, namentlich die Sitzungen der AG archivische Erschließung und der Agentur Standardisierung, den Deutschen Archivtag in Hof und den SODa-Selbstlernkurs Open Refine hin.
Die abschließende Umfrage bestätigte das Orga-Team bei ihren Planungen für ein 7. GND-Forum - das Interesse ist weiterhin rege! Verschiedene Themenvorschläge wurden bereits geäußert - „Überzeugen!“, „Motivieren!“, „Infrastrukturieren!“ oder „Steter Tropfen…“. Das Orga-Team nimmt die Rückmeldungen für das 6. und die Vorschläge für das 7. Forum in ihre weiteren Teamsitzungen mit und wird auch überlegen, ob das nächste Forum einmal wieder in Präsenz stattfinden kann. Über neue Gesichter im Orga-Team (egal aus welcher Archivgutsparte, egal aus welcher institutionellen Rolle heraus) freuen wir uns sehr. Nehmt bei Interesse einfach Kontakt mit uns auf!
Die Veranstalter des 6. GND Forums "Mitmachen!":

Die GND-Agentur SLSP mit verteilten Redaktionen
Die Swiss Library Service Plattform AG (SLSP) ist eine junge Einrichtung. Ende 2020 sind die von SLSP betriebenen Systeme Alma, Primo VE u.a. produktiv gegangen und lösten damit die Aleph-Systeme des Informationsverbundes Deutschschweiz (IDS) ab. Der IDS war strukturell eine Koordination von IDS-Teilverbünden, die einen gemeinsam verwalteten GND-Spiegel pflegten, während die bibliographischen Daten in ihren je eigenen Aleph-Systemen gehalten wurden. Mit SLSP hat sich die Situation systemtechnisch massgeblich vereinfacht. Die GND ist in der Community Zone in Alma zentral verwaltet und die bibliographischen Daten werden in der Network Zone in Alma von SLSP als ein Einheitskatalog gepflegt. Alma ist der primäre Zugang zu den bibliographischen und den GND-Daten. So überzeugend die technische Vereinfachung in der Arbeit mit der GND in Alma war, so komplex stellte sich die Implementierung letztendlich heraus. Aufbauend auf der Pionierarbeit des Österreichischen Bibliothekenverbund und Service GmbH (OBVSG) hat die Alma GND-Anwendergruppe (AGA) der Deutschsprachige Ex-Libris-Anwendergruppe (DACHELA) gemeinsam mit der DNB und Clarivate / Ex Libris die Systemarchitektur laufend verbessert, so dass wir heute eine funktionierende Umgebung haben.
Damit waren die organisatorischen Herausforderungen für die GND-Agentur SLSP noch nicht gelöst. Es war von Anfang an klar, dass SLSP als Servicedienstleisterin der technischen Infrastruktur für die Bibliotheken als einzige als GND-Agentur in Frage kam. Gleichzeitig hatte SLSP nicht die Ressourcen, in der GND-Agentur SLSP die Redaktionsarbeit selbst zu leisten. SLSP stand also vor der Frage, wie eine GND-Agentur mit ihren Rechten und Pflichten betrieben werden kann, ohne überhaupt irgendeine GND-Redaktion zu haben. Die Lösung bestand darin, dass SLSP den Expert Pool GND Editorial Board ins Leben gerufen hat, bestehend aus Personen aus den Bibliotheken, die in ihren Bibliotheksnetzwerken, die in Alma als Institution Zones (IZ) repräsentiert sind, die Redaktionsarbeit organisieren und die konkreten Aufgaben erledigen. Im Expert Pool GND Editorial Board sind die Redaktionen der IZs Region Zentralschweiz, Universitätsbibliothek Basel, Universitätsbibliothek Bern, Aargauer Bibliotheksnetzwerk, Universitätsbibliothek St. Gallen, Zentralbibliothek Zürich und ETH Zürich vertreten. Diese sieben IZs betreuen insgesamt mehr als 300 mit der GND arbeitende Institutionen.
Nicht jede Bibliothek, die mit der GND arbeitet, ist in einer IZ mit GND-Redaktion. Der Expert Pool GND Editorial Board hat dafür gesorgt, dass diese Bibliotheken Anschluss an eine Redaktion finden. Dabei ist es der GND-Redaktion selbst überlassen, mit der GND-nutzenden Bibliothek eine Vereinbarung abzuschliessen, die den Aufwand für die Betreuung regelt. Die Rechte und Pflichten sowie die Aufwandabschätzung haben der Expert Pool GND Editorial Board festgelegt. Ob die Leistungen der Redaktion kostenpflichtig sind, bleibt in der Entscheidung der Redaktion, ebenso die Höhe der Abgeltung, abhängig von der jeweiligen Kostenstruktur der Redaktion. So konnte zum Beispiel die IZ Zentralbibliothek Solothurn über die GND-Redaktion der IZ Universitätsbibliothek Bern an die GND-Agentur angeschlossen werden. Weitere Bibliotheken werden folgen.
Der Zugang zur GND ist in SLSP noch weiter geöffnet. Es gibt noch entferntere Institutionen, die keinen Zugang zu den Systemen von SLSP haben und trotzdem mit den Institutionen in SLSP eng zusammenarbeiten. Sie nutzen die GND via Webformular und sind via MOC (Marc Organization Code) an eine bestehende GND-Redaktion angeschlossen. Sie übernimmt dann die Pflege der über das Webformular angelegten Datensätze. Damit ist auf einfache Weise systemfremden Institutionen ein Zugang zur GND gegeben.
Die so strukturierte Organisation funktioniert nur, wenn die Erfassungs- und Redaktionsprozesse sowie die Workflows gut und transparent dokumentiert und vermittelt werden. Diese Arbeit leistet der Expert Pool GND Editorial Board zusammen mit der GND-Agentur SLSP. Für alle Beteiligten ist es eine Win-Win-Situation. Einerseits profitiert die GND-Kooperative von der Arbeit an der GND, andererseits können die beteiligten Institutionen etablierte Infrastruktur, funktionierende Prozesse und stabile Daten nutzen.
Sie erreichen die GND-Agentur der SLSP über diesen Link.

Die Archiv-Community rund um die Gemeinsame Normdatei (GND) ist sowohl engagiert als auch treu. Ein Beleg für diese Aussage: Wir stehen kurz vor dem sechsten GND Forum Archiv in fünf Jahren und erwarten wieder über einhundert interessierte Gäste. Es sollte Sie daher nicht überraschen, wenn das Motto unter dem dieses GND Forum steht, “Mitmachen!” lautet. Genau – mit einem Ausrufezeichen. “Mitmachen” ist nicht nur ein Label, mit dem man viele der Beiträge, die Teil des Programms sein werden, kennzeichnen kann, sondern zugleich eine Einladung an alle Institutionen und Mitarbeitenden im breiten Feld der Archive, die GND aktiv zu nutzen und mitzuwirken. Wie das möglich ist und was das möglicherweise an Arbeit und an Aufbau von Infrastruktur bedeutet, wird Gegenstand unter anderem des Publikumsgesprächs “Wann macht die Gründung einer GND-Agentur Sinn?” mit den Expert*innen sein. Eine Übersicht zum Programm bietet der Eintrag auf der GND-Website, alle Details zu den Referent*innen und Uhrzeiten hat die Interessengruppe Archiv im STA-Community Wiki veröffentlicht. Wie schon gewohnt, werden auch in diesem GND Forum die Formate Vortrag und Impuls mit Formaten der Publikumsbeteiligung rhythmisiert. Das heißt, direkt am 16. März 2026 im 6. GND Forum Archiv können auch Sie aktiv mitmachen.
Die Eckpunkte der Veranstaltung:
Termin: 16. März 2026, von 09:30 bis 13:00 Uhr
Ort: online, eine Anmeldung ist nicht erforderlich
Zielgruppen: Mitarbeitende und Interessierte in Archiven, Bibliotheken und darüber hinaus
Die Veranstalter sind:
Aufmerksame Fans des Formats bemerken sicherlich, dass seit dem letzten Forum (April 2025) ein neuer Partner hinzugekommen ist.

Zu den vorangegangenen GND-Foren Archiv:
#5 GND Forum Archiv, 4. April 2025 (Dokumentation)
#4 GND Forum Archiv, 23. September 2024 (Dokumentation)
#3 GND-Forum Archiv, 24. November 2023 (Dokumentation)
Heute wurde die vollständige Dokumentation zum Kolloquium des Standardisierungsausschusses "In Zukunft mit KI" veröffentlicht. Die Mitglieder dieses höchsten Gremiums zur Standardisierung von Meta- und Normdaten im Informations- und Wissensmanagements im deutschsprachigen Raum diskutierten offen und kontrovers die Frage der Bedeutung von Künstlicher Intelligenz für ihre Arbeit. Das Kolloquium fand am 10. Dezember 2025 an der Deutschen Nationalbibliothek in Frankfurt statt. Der digitale Tagungsbericht aggregiert aus den Abstracts, Visuals und Links zu den Vorträgen ein Wissensnetz zum aktuellen Stand KI-basierter Anwendungen in Bibliotheken in Deutschland und fasst die anschließende Diskussion zusammen. Besonders interessant dürften dabei die konkreten Ideen für die künftige Arbeit der Mitglieder sein.
Dokumentation zum STA-Kolloquium "In Zukunft mit KI"
Wir sind gespannt auf Ihre Kommentare.

Anfang des Jahres wurden die GND-Leitlinien in ihrer aktualisierten Fassung veröffentlicht. Das nehmen wir zum Anlass, um einerseits grundsätzlich die Funktion der Leitlinien darzustellen und andererseits zu erläutern, warum eine Aktualisierung nach Jahren geboten scheint. Die GND-Leitlinien sind ein integraler Bestandteil der GND-Kooperationsvereinbarung. Zusammenfassend ist es ihr Anliegen, allen Mitwirkenden an der GND einen klaren Handlungsrahmen zu vermitteln und zugleich allen Nutzenden offenzulegen, nach welchen Grundsätzen die Datensätze erstellt werden. Sie dienen demnach als Kompass oder neu-deutsch, sie sind der Code of Conduct der GND-Kooperative.

Ein GND Datensatz hat die Funktion eines verlässlichen Knotens im Netz der Daten.
Bildnachweis: https://pxhere.com/en/photo/646465; public domain
Seit der Erstveröffentlichung der Leitlinien 2017 als Anlage zur GND-Kooperationsvereinbarung hat die digitale Transformation des Kultur- und Forschungsbereichs enorme Fortschritte gemacht. Längst geht es nicht mehr vornehmlich um die Digitalisierung von Objekten, sondern die Daten zu den Objekten und die Referenzdaten selbst stehen im Fokus vieler kultur- und forschungsrelevanter Prozesse. Daneben sind Sichtbarkeit und Auffindbarkeit im Netz zu zentralen Parametern des Erfolges geworden. Das digitale Suchen und Finden (retrieval) von Daten und Information ist Teil unseres Alltags. Heute werden Informationen im zunehmenden Maß über KI-Agenten vermittelt. KI-Agenten sind oft Anwendungen generativer Künstlicher Intelligenz (KI). Ein bekanntes Beispiel ist der ChatGPT der Firma OpenAI. Aber auch Googeln passiert heute immer öfter im sogenannten AI-Modus. Bereits zwei Drittel der 16- bis 29-jährigen verwenden, laut einer Erhebung der bitkom, regelmäßig KI-Chatbots statt klassischer Suchmaschinen. Das ändert jedoch nichts am Anspruch des Nutzenden, dass die angebotene Information zuverlässig sein soll. Zuverlässig meint hier: faktisch richtig, nachvollziehbar und reproduzierbar. Dabei darf die Aussage “faktisch richtig” nicht zwingend mit “wahr” gleichgesetzt werden. Wahrheiten können, lehrt uns spätestens die Postmoderne, kontextgebunden sein. Fakten wie “Sauerstoff ist ein wesentlicher Bestandteil der heutigen Erdatmosphäre” sind hingegen beständig und dies unabhängig von der jeweiligen Perspektive des Senders oder Empfängers. Nur wenn diese Qualität der vermittelten Informationen verlässlich erreicht und vom Nutzenden auch tatsächlich wahrgenommen wird, werden KI-Agenten einen dauerhaften Beitrag in der Öffnung des Zugangs zu Wissen leisten und damit zu einem effektiven Assistenten in dem Aufgabenspektrum werden, das sie mit den Bibliotheken teilen: Die Vermittlung von Information und der Organisation von Wissen.
Diese technischen und damit einhergehenden gesellschaftlichen Entwicklungen wirken sich auf die Normdaten-Arbeit aus. Einerseits gilt es, das Retrieval in den KI-Suchen qualitativ zu sichern. Andererseits soll KI die automatische Erschließung fördern. Dabei Entitäten natürlich auch mit Normdaten verknüpfen und das Anlegen neuer GND-Datensätze unterstützen. Unbeantwortet bleibt hierbei bislang die Frage, welche Auswirkungen es auf unseren Umgang mit Daten, Informationen und Wissen hat, wenn Normdaten in KI-basierten Anwendungen automatisiert generiert und ebendiese im Retrieval als Referenz verwendet werden. Könnten Fehler sich dadurch leichter perpetuieren? Würden eigentlich falsche Daten zu fehlerhaften Ergebnissen führen? Diese Risiken gilt es, von einer soliden Basis aus bewusst in den Blick zu nehmen.
Normdaten sind und bleiben ein wichtiges Werkzeug des Retrievals im Informationsmanagement. Gerade im wissenschaftlichen Kontext erhalten Normdaten im RAG-Verfahren (Retrieval-Augmented Generation) zunehmende Bedeutung, um die Verlässlichkeit von Antworten der KI-Anwendungen zu verbessern. Dieses Verfahren wird jedoch noch nicht flächendeckend von den Sprachmaschinen angewandt. Vielmehr ist es bislang ein zusätzlicher Aufwand der Regulierung der Sprachmodelle (LLM), den der End-Nutzende nicht leisten kann. Zugleich verspricht man sich vom Einsatz KI-basierter Verfahren zur Generierung von Normdaten entsprechende Effizienzgewinne und setzt verstärkt auf ihre Implementierung (1). Das heißt, sowohl im Retrieval als auch bei der Generierung von Normdaten werden zunehmend KI-basierte Verfahren zur Anwendung kommen. Damit gewinnen die Nutzbarkeit und Zuverlässigkeit von Normdaten sowohl inhaltlich als auch technisch an zusätzlicher Bedeutung. Vor diesem Hintergrund verpflichten sich die Partner der GND-Kooperative in den GND-Leitlinien auf die Gewährleistung der Qualität der Normdaten im besonderen Maße und öffnen sich zugleich für KI-basierte Verfahren samt den daraus eventuell folgenden neuen Anforderungen an Dateiformate und Schnittstellen.
Keine alternativen Fakten in der GND
Die inhaltliche und technische Qualität der Normdaten ist das Fundament und konstitutives Element unserer transinstitutionellen Zusammenarbeit. Insbesondere die inhaltliche Verlässlichkeit betrifft die Verantwortung der Kooperative für unsere demokratische Gesellschaft. Wenn GND Redakteur*innen sich auf die Liste von Nachschlagewerken als Referenz berufen, dann steht dahinter die implizite Vorstellung, dass der Publikationsprozess von Nachschlagewerken hinreichend wissenschaftlich sei - also den ethischen Prinzipien der Wissenschaft (2) folgt, und damit innerhalb des gesellschaftlichen, zivilisierten Diskurses der Demokratie sowie ihres Fundaments aus Fakten, Menschenrechten und Verfassung. Dieser unausgesprochen vorausgesetzte Rahmen wird zwar als weitläufig, aber eben nicht als beliebig gesehen. Vielmehr vertraut man darauf, dass er eine hinreichende Meinungsvielfalt spiegelt, die sich jedoch auf eine Faktizität geeinigt hat, die nicht willkürlich, sondern belegbar ist. Dieser Rahmen gilt für die Wissenschaft, die Medien und nicht zuletzt für Wissensorganisationen wie Museen, Archive und Bibliotheken. Diese Prinzipien sind der Garant, dass nicht eine einfache Mehrheit oder ein Machthaber entscheiden kann, was faktisch richtig sein soll. Damit bieten diese Einrichtungen in unserer liberalen Demokratie ein korrigierendes Gegengewicht zum politischen Diskurs und schützen uns als Gesellschaft vor Fehlern. Das gilt selbst für solch kleine Elemente wie Normdaten. Vor dem Hintergrund der aktuellen gesellschaftlichen Entwicklungen schien uns die explizite Benennung dieses ethischen Handlungsrahmens geboten. Daher haben die Mitglieder der GND-Kooperative im GND-Ausschuss eine aktualisierte und abgestimmte Fassung der Leitlinien ausgearbeitet. Die aktualisierten Leitlinien betonen:
- Die GND verpflichtet sich zu wissenschaftlicher Redlichkeit, Quellentransparenz und sachlicher Darstellung.
- Ihre Partner sind hinsichtlich der Datenpflege und Dienstleistungen rund um die GND im Rahmen der liberalen Demokratie zu Neutralität und Unvoreingenommenheit im Sinne der allgemeinen Menschenrechte verpflichtet.
- Ihre Daten sind offen und frei im Internet zugänglich. … Sie unterstützt die Datenvernetzung über Regeln und Werkzeuge auch im Rahmen von KI-Anwendungen.
Der vollständige Text wird über die GND-Website zum Download angeboten.
Ich habe dem Beitrag ein Zitat des französischen Politikers und Abenteuers (sic!) André Malraux vorangestellt, weil das Zitat mir assoziativ eine Brücke schlägt von der uns vertrauten Welt der regelbasierten und normenden Daten, analog der Grammatik, zu der oft als chaotisch erlebten und auf jeden Fall machtorientierten Welt der Politik. Das Zitat lenkte meine Aufmerksamkeit auf das Risiko von Folgefehlern in der Politik. Denn auch die Politik hängt nicht zuletzt von der Richtigkeit der Fakten ab. Auf der Grundlage von verlässlichen Fakten sollte sie idealerweise ihr Handeln ausrichten. Andernfalls drohen auch in der Politik aus Fehlern neue Handlungsmaximen zu entstehen. Möge dies uns allemotivieren, redlich unser Handwerk zu betreiben.
Anmerkungen
(1) Vergleiche etliche Vorhaben der Mitgliedsintitutionen des Standardisierungsausschusses für KI-basierte Ansätze zur automatisierten Erschließung, die auf dem Kolloquium “In Zukunft mit KI” präsentiert wurden.
(2) Vergleiche Harari, Yuval Noah “Nexus”, Fern Press 2024, S. 103 “A scientific institution, in contrast, gained authority because it had strong self-correcting mechanisms that exposed and rectified the errors of the institution itself. It was these self-correcting mechanisms, not the technology of printing, that were the engine of the scientific revolution.”
 Der Handwerker, Bronze von Evelyn Beatrice Longman, 1931
Der Handwerker, Bronze von Evelyn Beatrice Longman, 1931
Bildnachweis: Steve Thornton, CC BY-SA 4.0, via Wikimedia Commons
{kind=link}
Ein kurzer Hinweis zum Schluss
Auf Wunsch von etlichen Nutzenden der GND-Website haben wir die Struktur der Infothek verändert. Sie folgt jetzt hoffentlich besser den Bedarfen der Nutzenden, indem sie deren mögliche Themen wie "Einführung in die GND", "GND Daten", "Vom Nutzen der GND" als Ordnungskategorien verwendet. Die GND-Leitlinien sind im Abschnitt "Über der Mitarbeit in der GND" veröffentlicht. Wir freuen uns über Ihr Feedback und bemühen uns zeitnah darauf einzugehen.
![]() Wenn Sie über neue Posts informiert werden wollen, dann abonnieren Sie bitte unsere Mailingliste GND-Kulturdaten über diesen Link: https://www.listserv.dfn.de/sympa/subscribe/dnb-afs-gnd-kulturdaten?previous_action=info
Wenn Sie über neue Posts informiert werden wollen, dann abonnieren Sie bitte unsere Mailingliste GND-Kulturdaten über diesen Link: https://www.listserv.dfn.de/sympa/subscribe/dnb-afs-gnd-kulturdaten?previous_action=info ![]()
Es ist Dienstag, der 23. Dezember, letzter Arbeitstag. Ganz nüchtern betrachtet ein Datum wie jedes andere. Und doch ist der letzte Tag des Jahres ein stiller Appell: Zeit für Rückblicke, Bilanzen und – natürlich – Checklisten der Key Results. Wann eigentlich kam diese Idee auf, man müsse zum Jahresende Rechenschaft ablegen? In unseren Breitengraden entstand sie mit hoher Wahrscheinlichkeit irgendwann zwischen der Vertreibung aus dem Paradies und der Einführung des Black Friday. Man darf annehmen, dass das Bilanzziehen sich nicht erst im Gefolge europäischer Kolonialherren über den Globus verbreitete, sondern vielerorts schon lange zuvor praktiziert wurde. Man zählt sein Hab und Gut, rechnet vor, was fehlt. Wenn man so viel besitzt, dass man seinen Besitz nicht mehr auf einen Blick erfassen kann, dann fängt man an, zu zählen, zu sortieren, zu kategorisieren und zu notieren … Yuval Harari beschreibt diese Entwicklung eindringlich in seinem Buch “Nexus”. Von der Organisation des Besitzes ist es nur ein kleiner Schritt zur Organisation des Wissens – und von dort zu den Normdaten. Da die Gemeinsame Normdatei zentrales Thema dieses Blogs ist, wäre das keine Überraschung.
Doch kehren wir noch einmal zur Ausgangsfrage zurück: Warum ausgerechnet am 31. Dezember? Warum nicht am 28. Februar? Auch da ist es kalt und trist. Man verpasst weder eine laue Sommernacht noch das Nachtigallenkonzert, wenn man sich stundenlang mit der Bilanz des vergangenen Jahres abmüht.
Wenn es draußen kalt und dunkel ist, spielen zumindest auf der Nordhalbkugel Lichter und Kerzen in vielen Bräuchen eine wichtige Rolle. Die schwedische Lichterkönigin trägt eine Kerzenkrone in das dunkle Haus. Man misst die Zeit mit dem Adventskranz oder dem Chanukka-Leuchter. Heute sieht man vermutlich vom Weltall aus, wann und wo der große Konsumaufschwung im Jahr stattfindet. Die festlich beleuchteten Straßen und Hausglitzerketten vertreiben das winterliche Dunkel. Ende Februar ist es zwar auch kalt und dunkel, aber die Aussaat steht kurz bevor, daher ist keine Zeit zum Bilanzieren, wendet die Anthropologie ein. Denn all diese Bräuche haben ihren Ursprung in der Naturbeobachtung der Altvorderen vor Tausenden von Jahren, unter anderem auf irgendeinem Hügel unweit von Leipzig.
Ist es nicht erstaunlich, wie stur traditionsgebunden unsere Gewohnheiten sind? Da kaufen wir Erdbeeren im Dezember und essen Nüsse im Sommer. Wir begeistern uns für Technologien, mit denen wir den von uns gemachten Klimawandel einhegen wollen. Wir fliegen als Touristen ins Weltall und schwadronieren von Marskolonien. Wir drehen die Heizung weiter auf, wenn es draußen stürmt. Und wir beschweren uns, wenn wir für die 600 Kilometer nach Frankfurt im Zug länger als vier Stunden brauchen. Und trotz all dieses Fortschritts, all dieser tollen Errungenschaften und fabelhaften Erfindungen sitze ich hier Ende Dezember und soll einen Jahresrückblick schreiben. Nur weil es vor Ewigkeiten mal bedeutsam war, wann die Sonnenwende erfolgte? Sie merken es vielleicht: Hier regt sich der Trotz der Angestellten. Der leise Unmut, auf den letzten Metern noch einmal eine Schippe drauflegen zu müssen. Bahnt sich da ein Konflikt an?
Nein halt! Denn eine Sache, die nicht nur mir besonders wichtig ist, sondern auch die Gäste des Kolloquiums des Standardisierungsausschusses unisono betonten, ist die Zusammenarbeit. Ohne Kooperation mit den erforderlichen Kompromissen, gegenseitigem Verständnis und Respekt sowie der Bereitschaft, dem anderen den Vortritt zu gewähren, wäre unsere Arbeit unmöglich zu bewältigen. Und da ja bekanntermaßen das Fest der Liebe vor der Tür steht, lassen wir die Revolte ausfallen. Stattdessen ein großes Dankeschön an all jene, die in den letzten 365 Tagen – mal mit, meistens ohne KI – enorm viel geleistet haben. Damit die Gemeinsame Normdatei das bleibt, wofür sie geschätzt wird: Ein verlässliches Werkzeug zur Wissensorganisation in einer Welt, die gern etwas heller sein dürfte.
P.S. Wer jetzt fragt: Wo ist die versprochene Checkliste zum Jahresende, mit der man prüfen könnte, wie die Bilanz der GND ausfällt? Dem empfehle ich für die hoffentlich ruhige und gemütliche Zeit der Raunächte die Lektüre aller Blogposts dieses Jahres. Da finden sich Informationen zu den Veranstaltungen, technischen Entwicklungen und Kooperationen, die zusammen dem Jahr 2025 zu einer positiven Bilanz verhelfen.
Frohe Festtage, einen guten Rutsch und auf ein Neues in 2026.

Aus der Reihe "Was du heute kannst besorgen ..." Der GND Weihnachtsgruß 2025 AfS (DNB) CC BY
Rückblick auf den Feedbackworkshop zur GND-Dokumentation am 24.11.2025
Mit der sukzessiven Veröffentlichung der Erfassungsregeln für die Normdatensätze der Gemeinsamen Normdatei auf der STA-Dokumentationsplattform im September hat die GND-Kooperative einen großen Schritt hin zur Fortschreibung ihrer Öffnung für die Expertise weiterer Communitykreise getan. In einem Workshop zur GND-Dokumentation bekamen Mitglieder aus Museen, Archiven und Forschungseinrichtungen, die mit der GND arbeiten, Gelegenheit, zu deren Struktur, Bedienfreundlichkeit und Verständlichkeit Feedback zu geben. Die Inhalte und Ergebnisse fasst dieser Blogpost zusammen.

Die Farbfolge eines Regenbogens folgt ganz ohne menschlichen Zutuns den immer gleichen Regeln.
Credit: Andrea Stöckel, public domain via public domain pictures
Von Regeln und ihrem Nutzen
Ein Regenbogen, die Schwerkraft und die Trägheit der Masse folgen den immer gleichen Naturgesetzen - auch wenn uns das Anthropozän gerade hier zum Umdenken zwingt. In zwischenmenschlichen Bereichen helfen Regeln, Konflikte zu vermeiden, Prozesse zu effektivieren und die Zusammenarbeit zu fördern. Oft genug sind es genau die Regeln oder besser die Befolgung derselben, die zu einer besseren Qualität führen. Sei es mehr Sicherheit im Straßenverkehr durch die Straßenverkehrsverordnung oder die Verwendung von genormten Material im Bau. Oder mehr Vergleichbarkeit durch standardisierte Ausschreibungsverfahren oder mehr Gerechtigkeit durch Gesetze, die für alle gelten. Die Reihe ließe sich beliebig fortsetzen. In der digitalen Transformation des Kulturbereichs ebenso in der Wissenschaft und Forschung sollen gemeinsame Standards, letztlich Regeln, für mehr Interoperabilität, Vernetzung und verbesserte Auffindbarkeit beziehungsweise Sichtbarkeit der digitalisierten Inhalte sorgen. Eine besondere Rolle nehmen hier Normdaten ein. Die Daten der Gemeinsamen Normdatei (GND) bieten den Vorteil, dass sie auch unabhängig von dem Stand der Standardisierung insgesamt bereits all das oben Genannte unterstützen. Sie sind sozusagen die Vorhut der Standardisierung. Dies erklärt den hohen Nutzungsgrad der GND-Daten als persistentes Referenzsystem in Kultur und Forschung im deutschsprachigen Raum. (weitere Informationen: Erste Ergebnisse der Umfeldanalyse wurden in Form eines Whitepapers veröffentlicht: Schlösser, M., Schäffer, J., von Hagel, F., & Schäfer, F. (2024). Überblick über das Forschungsdatenmanagement in Museen und Universitätssammlungen. Zenodo. https://zenodo.org/records/13789201)
Durch die verstärkte Nutzung der GND-Daten ergeben sich gerade in ihrer bedarfsorientierten Ansetzung auch erhöhte Bedarfe an neuen GND-Datensätzen oder an Ergänzung von bestehenden. Damit jedoch Normdaten ihre Referenzfunktion wirklich erfüllen können, müssen sie verlässlich sein. Diese Verlässlichkeit wird letztlich durch Regeln definiert und garantiert. Die Regeln, nach denen die GND-Datensätze angelegt werden, basieren wiederum auf internationalen Standards, niedergelegt im Regelwerk Resource Description Access – für den deutschsprachigen Raum in der Kurzform RDA DACH genannt. Vor der Veröffentlichung der STA-Dokumentationsplattform regulierte ein Lizenzmodell den Zugang zum RDA-Toolkit, mit dem Erschließende sich im Zweifel über die regelkonforme Darstellung von Katalogsdaten, wie Titel, Autor, Werk oder Ort, informieren konnten. Dieses Toolkit wurde ergänzt durch eine Vielzahl von aufeinander verweisenden und bezugnehmenden Textblättern, den Erfassungsleitfäden und Erfassungshilfen zur GND. Sich in diesem Geflecht zurecht zu finden war schwierig, auch wenn die Textblätter an sich über die Deutsche Nationalbibliothek allgemein zugänglich waren. Es ist daher nur folgerichtig, dass mit der Öffnung der GND auch die Regeln zu ihrer Erfassung transparenter, partizipativer und vor allem lizenzfrei zugänglich gemacht werden mussten. Mit der Veröffentlichung der Erfassungshilfen für Akteure, Geografika und Körperschaften in der GND-Dokumentation sind wir diesem Meilenstein erheblich näher gekommen. In den kommenden Monaten sollen die Regeln für Werke, Konferenzen und Sachbegriffe folgen.
Mit einer Workshopreihe begleitet die GND-Interessengruppe “Museen und Sammlungen” (IG MuS), unterstützt durch Mitarbeitende der GND-Zentrale, den Publikationsprozess. Eine Einführung in die Thematik erfolgte in dem ersten Workshop im Februar. Im Wesentlichen umreissen die beiden ersten Absätze des Blogposts die Perspektive der GND, wie das Thema im Workshop behandelt wurde. Der nebenstehenden Präsentation sind weitere Aspekte zu entnehmen.
Zum Lesen bitte auf die Abbildung klicken.
Vortrag zum ersten Workshop der IG MuS zur GND Dokumentation
Eine Einführung in die Arbeit mit der GND-Dokumentation
Für den Online-Workshop am 24. November konnten sich die Teilnehmenden aus der IG MuS und weitere Interessenten unmittelbar mit der GND-Dokumentation befassen. Dazu war zunächst eine Einführung in die Struktur der STA-Dokumentationsplattform mit ihren Bestandteilen Allgemeines, RDA DACH und GND erforderlich. Dies übernahm Andrea Hemmer (DNB). Sie erläuterte zu Beginn die inhaltlichen Abhängigkeiten zwischen RDA DACH und der GND am Beispiel von den Regeln zur Darstellung von Akteuren. Sie präsentierte unterschiedliche Möglichkeiten zur Suche und allgemein Begrifflichkeiten und Funktionalitäten der Plattform. Dann ging sie detailliert auf die Funktionen und Inhalte der GND-Dokumentation ein. Besonders relevant ist in diesem Zusammenhang, dass der bereits erprobte offene Redaktionsprozess für den Standard RDA DACH künftig auch Diskussionen zu den Regeln in der GND-Dokumentation ermöglicht. Damit können community-spezifische Bedarfe durch Anwendergruppen und solche allgemeiner Natur adressiert und transparent umgesetzt werden. Die gesamte text- und abbildungsreiche Präsentation ist nebenstehend nachzulesen.
Zum Lesen bitte auf die Abbildung klicken.
Die Folien von Andrea Hemmer (DNB) als PDF.
Feedback gewünscht
Zentrales Element des Workshops war selbstverständlich das eigenständige Testen der Dokumentation durch die Teilnehmenden selbst. Aufgeteilt in kleine Gruppen versuchten sie die nebenstehenden Aufgaben zu lösen. Ausgangspunkt war der Bedarf, einen regelkonformen GND-Datensatz zur Nadia Boulanger anzulegen.
Alle Teilnehmenden lösten die Aufgabe ohne Probleme. Der GND-Datensatz zu “Boulanger, Nadia” sollten mit dem Entitätencode piz, dem Ländercode XA-FXFR, den Lebensdaten * 16. September 1887 † 22. Oktober 1979 korrekt verknüpft werden, außerdem wären die Angaben zum Geburts-, Sterbe- und Wirkungsort als weitere Individualisierungsmerkmale, hier jeweils “Paris”, ebenso wie die Angabe ihres Berufes “Komponistin” ergänzt durch die Bezeichnung der Relationierung zu dem bereits vorhandenen GND Datensatz ihrer Schwester Lilli möglich. Die Leser*innen mögen selbst die Aufgabe in der GND-Dokumentation nachvollziehen, vielleicht zunächst ohne den in der obigen Lösung angegebenen Links zu folgen.
Natürlich fällt es jemandem, der nur sehr selten einen GND-Datensatz anlegen möchte, schwerer, sich in der Dokumentation zurecht zu finden als jemandem, zu dessen täglichen Aufgaben die GND-Arbeit gehört. Die Dokumentation bietet keine Eingabemaske für Entitätstypen, sondern bildet nur die Regeln zu deren Erfassung ab. Im Einzelfall kann eine detaillierte Schreibanweisung beim Anlegen von Datensätzen helfen. Neben kleineren Hinweisen zur Verbesserung der Verständlichkeit, wie der Erläuterung des Bibliotheksterms “Sucheinstieg”, lobten die Teilnehmenden die gute Verständlichkeit der Texte, die Erläuterungen mit Beispielen und das Farbkonzept zur leichteren Orientierung. Der für das zweite Quartal 2026 geplante dritte Feedbackworkshop wird sich dann den bis dahin hoffentlich vorliegenden Trainingsmaterialien zur GND-Doku widmen. Wir werden Sie informieren.
Bis dahin testen Sie gern selbst die GND-Dokumentation und lassen Sie uns Ihren persönlichen Kommentar zukommen. Auf jeder Seite der STA-Dokumentationsplattform finden Sie unten in der Menüleiste ein kleines Sprechblasen-Symbol; dies öffnet eine E-Mail an die Arbeitsstelle für Standardisierung mit dem entsprechenden Weblink in der Betreff-Zeile. Schreiben Sie uns, wenn Sie einen Tippfehler, einen Textfehler, eine Anmerkung oder ein Lob hinterlassen möchten. Wir freuen uns.
 Zum Lesen bitte auf die Abbildung klicken.
Zum Lesen bitte auf die Abbildung klicken.
Screenshot der Aufgaben im Feedbackworkshop zur GND-Dokumentation
Dokumentation des vierten projektübergreifenden Agenturentreffens am 30.9. 2025 an der Deutschen Nationalbibliothek in Frankfurt am Main
Erste Austausch-Runde
Alle Agenturen, Redaktionen und die GND-Zentrale hatten im Vorfeld Gelegenheit, sich zu den genannten Stichworten ihren Input zu überlegen und im Check In vorzutragen. Selbst neue Mitarbeitende konnten sich aufgrund der klaren Struktur gut in das Treffen einbringen. Es brauchte nur eine geringe Vorbereitungszeit und die alle betreffenden Themen wurden schnell offenbar.
Natürlich sind bei Teilnehmenden, die bereits seit Längerem im Netzwerk der GND arbeiten, die Perspektiven andere als bei denjenigen, die gerade im Aufbau oder noch in Planung sind. Dennoch kristallisierten sich klar Gemeinsamkeiten heraus. Ein Kernthema waren interne Workflows innerhalb der jeweiligen Agentur oder Redaktion. Wo diese noch konzipiert werden müssen, können die erfahrenen Agenturen beratend zur Seite stehen. So kann die Passung der inneren Workflows zu den Prozessen, die zwischen den etablierten Mitgliedern der GND-Kooperative bestehen, sichergestellt werden. Oft müssen jedoch die Konzepte noch umgesetzt und etabliert werden, ehe sie tatsächlich tragfähig sind und langfristig die Arbeit erleichtern. Die Prozesse innerhalb der GND-Kooperative waren ebenfalls Thema. Sehr deutlich wurde der Bedarf nach mehr Information und Transparenz sowie einer deutlichen Verkürzung der Prozesse. Das betrifft vor allem die Workflows bei Datenimporten und den Redaktionsprozess der GND-Regeln. Letzterer soll künftig transparenter und partizipativer werden, indem der funktionierende Releaseprozess für Redaktionsarbeiten an dem RDA-DACH-Standard in der STA-Dokumentationsplattform auch für die GND-Dokumentation übernommen werden soll.
Alle Beteiligten hatten Erfolge zu feiern. Die einen hatten ihr erstes Testdatenset erfolgreich in die GND eingebracht – ein wichtiger Meilenstein im Gründungsprozess einer Agentur. Andere freuten sich, für ihren Kundenkreis regelmäßig Schulungen anbieten zu können und aus diesem Kreis mit neuen GND-Datensätzen zum Reichtum und Vielfalt der GND beizutragen. Mehrere legten Konzepte vor, wie ihre GND-Anwendenden über Templates oder Datenaustauschformate leichter in der GND mitarbeiten können. Diese Konzepte werden nach Möglichkeit in die Planung zum Aufbau des von der GND-Zentrale verantworteten, neuen GNDcommunityspace einfließen. Hier gilt es am Ball zu bleiben.
Take-Aways aus der zweiten Runde
Die Themen, die alle betrafen, wurden in der zweiten Tageshälfte vertieft. Die Themen wurden in Barcamp-Manier aus dem Input des Check Ins durch die Abstimmung der Teilnehmenden identifiziert. An drei Tischen diskutierten die Teilnehmenden intensiv entlang der thematischen Linien “Workflows und Organisation”, “Workflows und Daten” sowie “Neuer Workspace zur Datenedition – aka GNDcommunityspace”.
Zentrales Thema war der Bedarf an Schulungen für Anwendende, die keine bibliothekarische Vorbildung haben. Die Hoffnung ist groß, dass es mit der Veröffentlichung der GND-Dokumentation leichter wird, GND-Datensätze regelkonform zu erfassen. Diese enthält die bisherigen GND-Erfassungshilfen und -Leitfäden zur Erfassung in den gängigen Softwareprodukten in Bibliotheken (PICA, Aleph und Alma). Indem wir uns auf die GND-Dokumentation fokussieren, sollte das große Desiderat Schulung zur GND für Nicht-Bibliothekare besser adressiert werden können. Der Anspruch ist auf jeden Fall, dass die Regeln intuitiver, leichter verständlich und die notwendigen Informationen leichter zu finden sein sollen als in den vormaligen PDFs. Die jetzt vorliegende Dokumentation der GND-Regeln wird in den kommenden Monaten erweitert und soll mit dem Feedback der Nutzenden verbessert werden. Bereits jetzt ist es möglich, online Rückmeldung zu einzelnen Seiten der GND-Dokumentation zu geben. Geplant ist zudem, für die Nutzung der Dokumentation Online-Trainingsmaterial zu entwickeln, das den Einstieg für alle, die nicht tagtäglich GND Datensätze bearbeiten, erleichtern soll.

Bild 1: Eindrücke aus der Bandbreite der geteilten Erfolge (Achieved):

Bild 2 Die Beiträge der Teilnehmenden im Check In zum Reinzoomen
Das zweite große Thema war eine verbesserte Dokumentation von Workflows. Das betrifft sowohl die generische Darstellung erwartbarer interner Workflows als auch die Darstellung, welche Anliegen über welche Workflows innerhalb der GND-Kooperative behandelt werden. Tatsächlich besteht hier noch ein Konzeptions- und Standardisierungsbedarf. Ein Thema, dem wir uns nur gemeinsam mit allen Beteiligten stellen können.
Das betrifft auch den Workflow zu den Datenimporten. Hier braucht es nach Meinung der Anwesenden mehr Transparenz, um zu verstehen, warum Importe so iterativ und zeitintensiv sind. Die dünne personelle Ausstattung der Deutschen Nationalbibliothek, die die Hauptlast der Integration neuer Daten in das Produktivsystem der GND trägt, ist nur ein Teil der Erklärung. Der andere Teil betrifft die technischen Rahmenbedingungen: Aktuell können lediglich Daten im Format MARC 21 und MARCXML per Batch importiert werden. Zudem prüft die GND-Kooperative die Qualität der gelieferten Daten anhand von Stichproben vor dem Import in die produktive GND, da die Datenqualität der GND im Interesse aller Beteiligten liegt. Vielleicht wäre es sinnvoll – so eine Anregung aus dem Plenum – Datenimporte community-spezifisch zu clustern und in vereinbarten Sprints – nach der Scrum-Methode – zu importieren. Das böte allen Beteiligten den Vorteil, sich nicht über einen längeren Zeitraum immer wieder neu in eine Thematik einarbeiten zu müssen. Andererseits ist es unerlässlich, dass alle am Prozess Beteiligten innerhalb des vereinbarten Zeitraums dieser Aufgabe die notwendige Zeit widmen. Eine weitere Anregung bestand darin, bei zeitkritischen Themen, dies bereits in der Betreffzeile einer Email an Mitarbeitende der GND-Zentrale entsprechend zu vermerken und im Text zu erläutern. Das böte den Mitarbeitenden der DNB die Chance, in der Pipeline der Anfragen zu priorisieren.
Der im Check In von mehreren Beteiligten geäußerte Bedarf an weiteren Templates zur regelkonformen und zugleich niedrigschwelligen Erfassung neuer Normdatensätze, ob zu Sachbegriffen, zu Geografika oder Provenienzdaten, harmoniert mit dem Vorhaben der GND-Zentrale eine technische Plattform zur kollaborativen Aggregation von Normdaten anzubieten, den GNDcommunity(data)space (GNDcs). Die Arbeiten dazu haben erst vor Kurzem mit der Beauftragung eines Dienstleisters begonnen. Im GNDcs sollen registrierte Mitarbeitende unterschiedlicher Communities die Möglichkeit haben, Kandidaten für die GND zu editieren. Es soll künftig Templates geben, die vorgeben, welche Angaben benötigt werden, um regelkonform Entitäten in der GND zu identifizieren und zu disambiguieren. Die von den Agenturen und Redaktionen erwähnten eigenen Konzepte für die Erfassung bestimmter Entitätstypen fließen nach Möglichkeit in die Entwicklung des GNDcs mit ein. Die Datensätze im GNDcs erhalten einen Identifier, der, sollte er in das Produktivsystem der GND übernommen werden, in der GND gespeichert wird. Entscheidender Vorteil wäre, dass im GNDcs noch unvollständige Datensätze angelegt werden können und man miteinander an der Vervollständigung arbeiten kann. Sobald eine Agentur den Datensatz auf die Eignungskriterien der GND hin überprüft und bestätigt hat, kann der Kandidat übernommen werden. Ein weiteres geplantes Funktionsfeld ist die Möglichkeit, im GNDcs ergänzende Angaben zu bestehenden GND-Datensätzen zu machen, die später zwar über den GND-Explorer angezeigt werden, aber nicht zwingend in das Produktivsystem der GND übernommen werden müssen. Schließlich ist auch ein Funktionsbereich für Korrekturen von bestehenden GND-Datensätzen geplant, die von einer Redaktion vor der Übernahme in das Produktivsystem geprüft werden. Eine erste Beta-Version mit funktionsfähigen Teilbereichen der Anwendung wird für Anfang 2026 erwartet.
Die Logos der entsendenden Einrichtungen und Konsortien







![]()


Eine Anregung galt dem Angebot des Informations- und Lernmaterials, das unter anderem auf der GND-Website vorliegt. Hier würden kategorisierende Etiketten, wie “Einführung” und “Archive”, helfen, sich im Angebot schneller zu orientieren. Bei der anstehenden Überarbeitung der GND-Infothek soll diese Anregung aufgegriffen werden.
Schließlich noch ein Hinweis: Viele neue GND-Anwendende haben die meist nur gedruckt vorliegenden Nachschlagewerke, auf die die GND-Dokumentation regelmäßig Bezug nimmt, aus Kostengründen nicht zur Hand. Zudem erscheinen gerade Fachcommunities die in der Liste der Nachschlagewerke verzeichneten Titel als zu allgemein oder gar veraltet. Das heißt, für die Redaktion dieser Liste müsste der Prozess partizipativer und transparenter gestaltet werden. Dies könnte gegebenenfalls künftig im Rahmen des Releaseprozesses der Änderungen der GND-Dokumentation adressiert werden. Zuvor muss jedoch definiert werden, wer genau die Mitwirkenden, neben den Mitgliedern des GND-Ausschusses, in diesem Releaseprozess sein werden.
Zum Schluss des langen Tages
Nachdem im Plenum die Ideen und Ergebnisse aus dem Barcamp zusammengetragen worden waren, galt es zum Schluss des langen Tages Bilanz zu ziehen und Verabredungen für die Zukunft zu treffen: Die Praxis der jährlich stattfindenden projektübergreifenden Agenturentreffen soll beibehalten werden. Und als Angebot der bereits im Dauerbetrieb agierenden neuen Agenturen – LEO-BW-Regional, Bauwerke und data4kulthura – soll ein “Jour Flexe” für alle Interessierten eingerichtet werden, um den lockeren Austausch kontinuierlich zwischen den vor Ort stattfindenden Agenturentreffen zu fördern.

Bild 3 Die Mitarbeitenden aus den neuen Agenturen und Redaktionen sowie der GND-Zentrale in der Herbstsonne. Credit: A.Steckel (SUB), CC BY, 2025
Wenn ein hydraulischer Obstschüttler in der Apfel- oder Olivenernte zum Einsatz kommt, dann prasseln mit viel Krach die Früchte auf die Erde, Äste brechen und manch ein Apfel zerplatzt im Sturz. Wer das von Tracy Arndt in der Infrastruktur der Deutschen Nationalbibliothek (DNB) angepasste und implementierte Tool zum "Cherry-Picking" in der Gemeinsamen Normdatei (GND) zum Einsatz bringt, hört kaum das Schnurren des Computers und nicht ein Datensatz zerbricht. Tracy Arndt ist Bibliotheksinformatikerin und verantwortet in der DNB den Linked Data Service. Erst kürzlich wurde der so genannte SPARQL Endpunkt zur GND und den Titeldaten der DNB in einer Betaversion veröffentlicht. Sie hat mir im Interview erklärt, wie dieses Tool funktioniert und was für sie in diesem Kontext “Cherry-Picking” bedeutet.
 Zum Vergrößern auf das Bild klicken
Zum Vergrößern auf das Bild klicken
Ein hydraulischer Obstschüttler in Aktion credit: Feucht Obsttechnik
Barbara: Tracy, was genau ist ein SPARQL Endpunkt?
Tracy: Ein SPARQL Endpunkt ist ein Webdienst, über den mit der standardisierten Abfragesprache SPARQL auf strukturierte Metadaten im Format RDF zugegriffen werden kann – einem Modell, das Informationen als Tripel (Subjekt – Prädikat – Objekt) speichert und damit leicht von Maschinen verarbeitet werden kann. Anders gesagt, mit Hilfe einer SPARQL Abfrage kann ich über eine oder mehrere Datenquellen gleichzeitig nach Datensätzen suchen und das Ergebnis als Liste exportieren, die alle dieselben von mir definierten Kriterien erfüllen. Beispielsweise kann ich mir eine Sammlung erstellen lassen, aus der die Verteilung bestimmter Geburtsjahrgänge laut der Datenquelle in einem bestimmten Berufsbild hervorgeht. Aber auch alle Personen, die vor 1960 geboren wurden, als Auszug exportieren.
Für wen ist der Service?
Im Prinzip können alle diesen Abfragedienst nutzen. Besonders relevant ist er vermutlich für Mitarbeitende in Bibliotheken, in der Forschung und im Kulturbereich. Gerade Entwickler*innen, die die Such-Ergebnisse in eine eigene Anwendung einbinden wollen, profitieren vom schnellen und maschinenfreundlichen SPARQL Service. Mit etwas Geschick können Laien, die die Ergebnisse ihrer facettierten Suche anstatt sie sich im Explorer nur anzeigen zu lassen, diese als Tabellenblatt oder im JSON-Format über den SPARQL Endpunkt exportieren. Diese Form der definierten Exports kommt dem englischen Ausdruck “cherry-picking” doch recht nah.
Wie sieht ein typischer Usecase aus?
Eine Person oder eine Anwendung, die aus den Datenquellen GND oder/und Titeldaten der DNB einen präzisen Teilbestand identifizieren möchte, dürfte das Gros der Nutzenden ausmachen.
Gibt es eine Art “Übersetzungsdienst”, damit Menschen ohne Vorkenntnisse eine SPARQL Abfrage formulieren können? Oder verlässt man sich lieber auf einen KI-Chatbot?
In einem ersten Schritt kann man sich an den Beispielen, die auf der Website angegeben sind, orientieren und daraus die eigene Abfrage ableiten. Im Netz gibt es viele Anleitungen für das Abfassen von SPARQL Abfragen. Zudem betreue ich aktuell ein studentisches Softwareprojekt an der HTWK Leipzig. Die Studierenden programmieren eine Anwendung, die natürlich-sprachige Anfragen an die GND in eine SPARQL Query übersetzen und dann die Antwort auch natürlich-sprachig wiedergeben. Also eine Art Chatbot. Wenn man beim formulieren von SPARQL Queries allgemein Unterstützung braucht, kann natürlich auch ein marktüblicher Chatbot helfen. Bei der Übernahme der Tipps muss man jedoch darauf achten, dass man das in der GND gängige Vokabular verwendet. Zum Beispiel die korrekten Bezeichnungen der Entitätstypen oder die in der GND verwendeten Eigenschaften. Entsprechend gilt das für die in den Titeldaten verwendeten Labels, damit diese bei der Suchabfrage des SPARQL Services gefunden werden. Der normale Chatbot wird hier nicht exakt den richtigen Code liefern, sondern im Zweifel eigene Bezeichnungen halluzinieren.
Gibt es eine Möglichkeit, mir Veränderungen der Ergebnisliste der Suchabfrage im Zeitverlauf anzeigen zu lassen? Wenn man beispielsweise regelmäßig mit derselben Suchanfrage den Dienst benutzt, kann ich dann Veränderungen im Zeitverlauf kenntlich machen?
Weder in der GND noch in der Titeldatenbank werden Versionsverläufe in einer einfachen Modellierung abgebildet. Daher lassen sich derzeit Zeitverläufe nicht so gut über SPARQL Abfragen abbilden.
Zum Vergrößern auf das Bild klicken
Poster zum SPARQL Enpoint von Thomas Bauer und Tracy Arndt, DNB, CC BY, 2025
Der SPARQL Service greift sowohl auf die Daten der GND in Verbindung mit anderen Daten namentlich den DNB-Titeldaten zu. Kann ich die beiden Datenquellen auch getrennt adressieren? Also nur GND oder nur Titeldaten? Kann ich weitere Datenquellen inkludieren, beispielsweise Wikidata? Und wenn ja, wo finde ich hierfür eine Anleitung?
Auf der Website des SPARQL Services ist die Auswahl vorprogrammiert entweder nur in der GND oder kombiniert mit den Titeldaten der DNB die Suchabfrage laufen zu lassen. Siehe Screenshot.
Das tolle an dem Datenformat RDF ist, dass man Daten über URIs - also Links - untereinander referenzieren kann. Das bedeutet, dass wenn ein anderer Datensatz diese URI nachnutzt, kann ich an die Informationen kommen, die dahinter stehen. Am besten sieht man das an unseren Titeldaten. Dort ist beispielsweise der Autor eines Titels mit der GND verknüpft. Dort ist der Autor wiederum verknüpft mit einem Ort. So kann man eine Datenliste mit den entsprechenden Namen und Buchtiteln als Antwort auf die Frage bekommen: “Welche Bücher wurden von Berliner Autorinnen geschrieben?"
Gibt es Informationen darüber, wie oft der Service genutzt wird?
Ja, wir erfassen die Zugriffe. Diese werden nur über die IP Adressen geloggt, aber nicht von uns entschlüsselt. Uns interessiert hier mehr, was abgefragt wird und überhaupt nicht, wer die Abfrage stellt. Die Daten sind hinreichend anonymisiert, so dass man von einer DSGVO konformen Datenhaltung ausgehen kann.
Welche Rolle spielt die GND Ontologie?
Die GND Ontologie enthält die Beschreibung der Daten und wie sie miteinander in Beziehung stehen. Dort kann man sehen, welche Eigenschaften verwendet werden. Beispielsweise: preferredNameOfThePerson oder DateOfBirth. Daher spielt die GND Ontologie eine zentrale Rolle, da über die Ontologie die Strukturen des Wissensgraphen geformt werden. Bei den Titeldaten verwenden wir nach internationalen Standards für denselben Zweck externe Vokabulare.
Wie ist der Endpunkt technisch aufgebaut?
Über monatliche Datendumps aus unseren internen Daten werden RDF Daten erzeugt und anschließend mit der SPARQL Engine Qlever indexiert, um eine schnelle Suche darauf durchzuführen.
Gab es Schwierigkeiten bei der Konzeption und Implementierung?
Wir haben lange nach einer geeigneten Software gesucht, um einen SPARQL Endpunkt anbieten zu können. Aufgrund der Größe der Datendumps, insbesondere unserer Titeldaten, haben sich aber immer wieder Performance Probleme gezeigt. Der Service wäre zu langsam gewesen. Mit der SPARQL Engine Qlever tritt das jedoch nicht auf und wir können endlich einen performanten Endpunkt anbieten.
Wie oft werden die Daten, auf die der SPARQL Endpunkt zugreift, aktualisiert?
Die GND Daten und Titeldaten, die für die SPARQL Abfragen genutzt werden, werden monatlich frisch hochgeladen.
Und zum Schluss wo finde ich mehr Information?
Ergänzend zur Website stellen wir weitere Informationen im DNB Wiki bereit und freuen uns über Feedback von den Nutzenden.
Das Gespräch führten Tracy Arndt und Barbara Fischer.
 Zum Vergrößern auf das Bild klicken
Zum Vergrößern auf das Bild klicken