Im April 2024 hat Yvonne Tunnat (ZBW) Monika Zarnitz von der AG Community Survey für den nestor Podcast interviewt. Diese Folge ist bei YouTube verfügbar.
Es gibt dazu ein automatisiert erstelltes Transkript, das mit beim Anschauen mitläuft, aber auch hier nachgelesen werden kann.
ytunnat
Herzlich willkommen zum nestor Podcast. Heute geht es um eine nestor AG, eine Arbeitsgruppe, und zwar zum Thema Communities. Und ich habe zu Gast meine Kollegin Monika Zarnitz. Wir sind beide von der ZBW. Ich bin Yvonne Tunnat von der ZBW. Monika Zarnitz arbeitet auch an der ZBW.
Wir haben sogar ziemlich viele gemeinsame Aufgaben hier. Und ich freue mich, Monika, dass du heute hier bist, um über die nestor AG zu berichten. Und ja, stell dich doch gerne erst mal selbst vor und dann frage ich dich zu AG aus.
Monika
Ja, also erstmal vielen Dank für die Einladung, diesen Podcast aufzuzeichnen. Das ist doch eine ganz interessante Angelegenheit. Ich selbst bin ausgebildete Volkswirtin und bin 1994 in die ZBW gekommen, habe da verschiedene Funktionen gehabt und bin heute Programmverantwortliche für Benutzungsdienste und Bestandserhaltung. Und in der Abteilung Bestandserhaltung ist auch unsere digitale Langzeitarchivierung angebunden. Deshalb diese Verbindung zur digitalen Langzeitarchivierung.
Monika
In nestor bin ich eingebunden, dadurch, dass ich die ZBW in der Koordinationsrunde vertrete. Ich leite die Arbeitsgruppe Community Survey, über die heute zu berichten sein wird und ich bin auch noch Mitglied in der AG PDA, also Personal Digital Archiving, wo es darum geht, für die breite Öffentlichkeit Angebote zu machen, um sie in die Lage zu versetzen, ihre eigenen persönlichen Daten auch dauerhaft zur Verfügung zu haben.
ytunnat
Ich glaube, es ist auch fair zu sagen, dass die ZBW schon ungefähr seit 14 Jahren bei nestor aktiv ist. Ich persönlich seit 13 Jahren und du mindestens seit 2015. Genau. Mich interessiert jetzt, wie es zu der AG-Community gekommen ist.
Monika
Ja, das fing eigentlich mit einer Idee an. Die ist entstanden daraus, dass vor einigen Jahren die zentralen Fachbibliotheken, das sind also die TIB, die ZB MED und die ZBW eine Informationsveranstaltung durchgeführt haben für die Bibliotheken und Informationseinrichtungen der Leibniz-Gemeinschaft. Damals war die Idee, über die digitale Langzeitarchivierung zu berichten und zu vermitteln, wie sich die Kolleg:innen in den anderen Einrichtungen diesem Thema nähern können. Alle von uns, das war eine Gruppe von Leuten, die das vorbereitet hat, hat kleine Präsentationen zu verschiedenen Themen vorgetragen und ich hatte die Idee, eine Präsentation zu Vernetzungsmöglichkeiten in Communities der digitalen Langzeitarchivierung vorzustellen.
Mir war das deshalb so wichtig, weil man gerade, wenn man beginnt, sich mit der digitalen Langzeitarchivierung zu befassen, erst Wissen aufbauen muss. Die digitale Langzeitarchivierung ist ein komplexer Prozess und die Vernetzung, um Wissen aufzubauen, war mir einfach sehr wichtig. Also genau dann, wenn man sich neu in das Thema einarbeiten möchte.
Als ich von der Veranstaltung zurückfuhr, dachte ich im Zug noch ein bisschen darüber nach und kam dann auf die Idee, dass es nützlich wäre, eine weltweite Übersicht zu Communities für die digitale Langzeitarchivierung zu haben. Das wäre eine sehr praktische Angelegenheit.
Monika
Und so eine Übersicht könnte man über eine Umfrage unter den Communities erstellen und die Ergebnisse kann man in aggregierter und anonymisierter Form zur Verfügung stellen oder eben auch als ein sogenanntes Profil. Das heißt, die Darstellung einer einzelnen Einrichtung mit ihren Merkmalen, die man in den Open Access stellt, und in der man nachgucken kann, welche Community für einen selbst die interessanteste ist. Und das haben wir dann im Laufe der Zeit umgesetzt.
ytunnat
Und es sind ja noch mehr Mitglieder in der AG inzwischen, nicht nur die drei von dir bereits genannten Institutionen. Wie hat sich denn die Gruppe zusammengefunden und wer ist drin?
Monika
Das war im Grunde ganz einfach. Nachdem ich mir also diese Gedanken gemacht hatte, habe ich die Leiterin der Geschäftsstelle von nestor angesprochen. Das war damals die Sabine Schrimpf und habe am Rande der nächsten Besprechung der Koordinationsrunde von nestor gefragt, ob das nicht ein Thema für nestor wäre und ob sie mir hilft, einen Kreis von Personen zusammenzustellen, die sich für so ein Projekt engagieren könnte. Dann haben wir auf derselben Sitzung alle gefragt und es kam eine Gruppe zusammen, die damals aus der Sabine Schrimpf selbst bestand. Thomas Bähr und Micky Lindlar von der TIB, sowie Stefan Strathmann von der Niedersächsischen Staats- und Universitätsbibliothek in Göttingen. Wir haben den ersten Survey zusammen durchgeführt und dann eine richtige nestor AG ins Leben gerufen, um das ganze Projekt auch ein bisschen zu verstetigen. Und heute besteht diese Gruppe aus Svenia Pohlkamp, das ist die derzeitige Leiterin der nestor-Geschäftsstelle und Merle Friedrich von der TIB und Stefan Strathmann ist uns auch treu geblieben und mir selbst. Ich bin diejenige, die die ganze AG so ein bisschen koordiniert.
ytunnat
Und damit wir jetzt auch wirklich alle abholen und weil der Begriff ja auch gegebenenfalls ziemlich breit ist. Wie definiert ihr denn? Wie definiert eurer AG den Begriff Community?
Monika
Das war eine sehr wichtige Frage am Anfang. Wir haben lange darüber diskutiert, wie wir das Ganze abgrenzen wollten, denn wir brauchen klare Einschluss- und Ausschlusskriterien für die Umfrage und für die Profile, die wir erstellen wollen. Wir haben dann schlussendlich folgende Definition gefunden.
Monika
Eine Community für die digitale Langzeitarchivierung ist eine offene Gemeinschaft von Personen und / oder Institutionen, die sich mit dem Thema digitale Langzeitarchivierung befassen, so zum Beispiel nestor.
Die digitale Langzeitarchivierung kann eins von mehreren Themen sein, mit der sich die Gemeinschaft befasst. Es kann aber z. B. sein, dass das eigentliche Hauptanliegen dieser Community der Betrieb eines fachlichen oder institutionellen Repositoriums ist und die digitale Langzeitarchivierung dafür natürlich wichtig ist und auch umgesetzt werden soll, aber im gesamten inhaltlichen Spektrum dieser Community eher ein Teil ist.
Und diese Offenheit des Gemeinschaftsgedankens ist hier auch wichtig, denn es gibt einzelne Einrichtungen, die etwas für die digitale Langzeitarchivierung in kooperativer Form tun. Zum Beispiel die zentralen Fachbibliotheken, die gemeinsam ein Langzeitarchiv unterhalten für ihr eigenes digitales Material. Aber die würde man nicht unbedingt als Community bezeichnen. Das ist eine Kooperation im engeren Sinne.
Ja, und eine Community ist eben auch eine Gemeinschaft, deren Mitglieder sich für die digitale Langzeitarchivierung verantwortlich fühlen in einer Art, die über das reine Eigeninteresse hinausgeht.
Und der zentrale Zweck besteht nicht nur darin, ein Produkt oder einen gewerblichen Dienst anzubieten. Das ist so ein Aspekt, den wir eingeführt haben, weil wir reine Firmen von dieser Definition der Community ausschließen wollten. Also Ex Libris für sich betrachtet ist keine Community. Aber eine Community ist z. B. die Rosetta Anwender Group, die Deutsche zum Beispiel.
ytunnat
Ja, das stimmt.
Monika
Genau und die Community kann auch eine Plattform sein, auf der Themen der digitalen Langzeitarchivierung und die Frage, wie die digitale Langzeitarchivierung weiterentwickelt werden kann, diskutiert werden. Auch die Entwicklung von Tools oder die Bereitstellung von Diensten kann Thema einer Community für die digitale Langzeitarchivierung sein. Um ein Beispiel zu geben: Jhove ist ein Tool, das man für die Format Erkennung und Validierung einsetzt und das von der Open Preservation Foundation betreut wird und von dieser Community auch weiterentwickelt wird.
Es gibt noch andere Dienste, nestor zum Beispiel bietet ein Siegel an, ein Qualitätskennzeichen für Einrichtungen, die ein eigenes digitales Langzeitarchiv haben, und das ist auch ein Dienst, aber es ist einer von vielen und es ist etwas, was nicht kommerziell angeboten wird.
Ja und Communities können schlussendlich lokal agieren, national, international. Sie können klein sein. Wir haben zum Beispiel in Köln einen Stammtisch zur digitalen Langzeitarchivierung oder im Vergleich groß sein wie die Open Preservation Foundation, die mehrere hundert Mitglieder hat.
Die Communities können auf ein Produkt bezogen sein, zum Beispiel diese Deutsche Rosetta Anwendergruppe oder eben unabhängig von irgendeiner Form von Produkt sein.
Es ist ein sehr breites Spektrum, sehr viele Ansätze. Wir haben auch festgestellt, dass viele Einrichtungen, die heute digitale Langzeitarchivierung betreiben, schon sehr lange existieren, also lange bevor dieses Thema überhaupt wichtig wurde.
Es gibt viele Facetten und der Community Survey ist schlussendlich auch entwickelt worden, um diese Facetten einmal transparent zu machen und im Vergleich darzustellen, wie sich einzelne Communities geformt und aufgestellt haben.
ytunnat
Das hast du so ein paar genannt, die mir auch sofort eingefallen wären. Ihr habt aber noch, wie viele Communities habt ihr eigentlich beim ersten Durchgang gefunden? Oder wie viele Antworten habt ihr bekommen?
Monika
Vielleicht sollte ich erst mal erzählen, wie wir die Antworten eingesammelt haben. Wir hatten also einen Online-Fragebogen ausgearbeitet und haben den über Verteilerlisten verteilt und dann gab es einige von uns in dieser AG, die sehr viele ausländische Kontakte hatten und die haben dann direkt Bekannte und Freundinnen angemeldet und angesprochen, um sie zu bewegen, diese Umfrage auszufüllen. Es ist aber ein sehr langer Fragebogen. Wir haben 40 Fragen gehabt und das war schon ein Angang für diese Einrichtung, den komplett auszufüllen. Und es war wohl der Grund auch dafür, dass es etwas mühsam war, eine halbwegs hohe Anzahl ausgefüllter Umfrageergebnisse zusammen zu bekommen.
Und wir haben auch mehrfach Erinnerungen an die zu Befragenden verschickt. Am Ende hatten wir ungefähr 55 valide Angaben, was auch 55 unterschiedlichen Communities entspricht. Aber man muss das Ganze auch ein bisschen relativieren, denn man muss im Hinterkopf haben, dass die digitale Langzeitarchivierung ein sehr spezielles Gebiet ist. Daran gemessen sind 55 Communities weltweit schon eine ganze Menge.
Und die Größe der Grundgesamtheit kennen wir leider gar nicht.
ytunnat
Also das heißt, in eurer AG war schon eine gewisse Expertise vorhanden, wo vielleicht Communities sein könnten. Und dadurch habt ihr das ein bisschen weiter gestreut, jetzt nicht nur Europa und USA, worauf man sofort kommt, sondern auch ein bisschen auf anderen Kontinenten.
Monika
Ja genau, das haben wir versucht. Es war nur so, dass die Schwerpunkte im Grunde doch in Europa, in Nordamerika lagen. Ich glaube, wir hatten noch jemanden aus Südafrika dabei und aus Japan und dem Pazifischen Raum.
Es war einfach so, dass es wieder eine Angelegenheit der Industriestaaten war. Die waren besonders gut repräsentiert und was wir eben nicht wissen ist, was mit den anderen Staaten ist, ob die Leute da vielleicht tatsächlich auch selbst kleine Communities haben. Sie haben sich jedenfalls nicht gemeldet.
Und die andere Möglichkeit für diese Leute ist es ja auch, sich anzuschließen an internationale Communities und von deren Dienstleistungen zu profitieren. Und das müsste man eigentlich ein bisschen hinterfragen und nochmal hinterherhaken, aber in Asien, Lateinamerika und Afrika scheint da nicht so viel zu sein. Oder wir haben sie nicht erreicht? Das ist die andere Möglichkeit.
ytunnat
Ihr macht aber ja auch noch weiter, es wird ja einen zweiten Durchgang geben.
Monika
Ja, auf jeden Fall. Der zweite Durchgang ist schon in der Auswertung. Wir hatten im Juni letzten Jahres, 2023, dieselbe Umfrage an die Quellen geschickt, die uns bekannt waren, haben dann aber auch noch erinnern müssen, und im November haben wir dann die Umfrage auch geschlossen. Diesmal ist es nur so, dass wir 32 vollständig valide Datensätze zusammenstellen konnten. Es sind zum Teil Communities dabei, die in der ersten Umfrage nicht vertreten waren.
Und wir haben bei der Umfrage vollständigere Ergebnisse bekommen und gehen eigentlich davon aus, dass die Ergebnisse damit auch ein bisschen belastbarer sind, also aussagefähiger als Teile der ersten Umfrage.
ytunnat
Sind das dann nicht nochmal dieselben 40 Fragen gewesen, sondern ein bisschen anders?
Monika
Wir haben ein bisschen variiert in verschiedener Form. Einmal haben wir einige Fragen weggelassen, bei denen wir zur ersten Umfrage keine vernünftigen Ergebnisse bekommen haben und es auch unwahrscheinlich war, dass da eventuell noch etwas möglich wäre. Wir haben einige Fragen umformuliert, um sie etwas klarer zu formulieren, weil wir bei der ersten Umfrage Rückfragen erhalten hatten zu diesem Punkt.
Und ich muss überlegen. Genau, das gab Fragen, die wir ein bisschen uminterpretieren mussten, damit sie verständlicher waren. Und dann haben wir Kleinigkeiten anders gemacht. Wir hatten zum Beispiel für die Anzahl von Kooperationspartnern in der ersten Umfrage ein Freitextfeld eingegeben, weil wir noch nicht so gut wussten, mit welchen Mengen wir da rechnen würden und haben in der zweiten Umfrage dann Brackets vorgegeben. Da mussten die Leute angeben, von 0 bis 5, von 6 bis 12 oder so etwas. Und das konnten die anhaken und das war zum einen für die, die den Fragebogen ausfüllen wollten, sehr viel einfacher zu handhaben und für uns war die Auswertung an dem Punkt dann auch einfacher. Und in der stecken wir derzeit.
ytunnat
Ihr seid ja auch unglaublich viel nach draußen gegangen und habt da dazu Vorträge gehalten. Könntest du noch mal ein bisschen aufzählen, wo du oder deine Kolleg:innen überall gewesen seid, um darüber zu sprechen?
Monika
Ja, also wir waren auf der Liber Konferenz 2022 in Odense, in Dänemark, dabei und haben das Projekt vorgestellt und wir haben bei der virtuellen Geburtstagsveranstaltung der Open Preservation Foundation 2020 auch einen Vortrag gehalten. Also das haben wir gemacht, um das Ganze auch ein bisschen zu promoten, um das es ein bisschen bekannt zu machen.
ytunnat
Gab es nicht auch bei der Ipres in Glasgow was, was Micky Lindlar? Haben sich dann aufgrund der Vorträge dann eigentlich noch mal Communities gemeldet, die sich bis jetzt, also die ihr noch nicht auf dem Schirm hattet?
Monika
Ja, da hat Micky Lindlar was gemacht, das stimmt ja.
Nein, das leider nicht. Aber da muss ich sagen, hätte ich mir am ehesten von der Ipres eine entsprechende Rückmeldung erwartet. Die Liber Konferenz ist ja eher so auf das allgemeine Bibliotheksgeschehen ausgerichtet und da kam nichts. Natürlich Rückfragen zu dem Vortrag, das schon, aber nicht so, dass da jemand gesagt hätte, ach, ich gehöre zu einer Community, ich möchte gerne bei euch mitmachen.
Und bei der Open Preservation Foundation, das war eine virtuelle Veranstaltung und ich weiß nicht, ob das so der Rahmen ist, am Rande über Teilnahme an den Community Service zu sprechen. Da ist auch nichts Konkretes nachgekommen.
ytunnat
Als du das beim nestor Praxis Tag 2023 vorgestellt hast, da kamen ja zwar Ideen, wo es noch Lücken gibt, aber keine, wie man sie füllen kann. Also es hat niemand gesagt, ah, ich kenne zufällig eine Community in Lateinamerika oder so, was natürlich cool gewesen wäre, aber ja, schade. Ich hätte auch gedacht, dass die iPres vielleicht mehr, weil da ja doch aus sehr vielen unterschiedlichen Ländern Leute kamen, aber vielleicht ist Glasgow dann auch zu europäisch gewesen, vielleicht hätte das, wäre das dann in Boston besser gelaufen, aber Boston war ja auch 2018, da gab es ja dann eure AG noch gar nicht.
Monika
Ich denke, man musste auch ein bisschen Geduld haben und immer wieder am Ball bleiben und das Ganze auch immer wieder mal an irgendwelchen zentralen Konferenzen vorstellen. Wir wollen uns auf jeden Fall für die dritte Umfrage, die ja hoffentlich auch irgendwann kommt, noch einen Weg ausdenken, wie wir Communities direkter ansprechen können, wie wir das Marketing sozusagen verändern. Möglicherweise müssen wir individueller eingehen, auf die Ansprechpartner:innen zugehen und solche Dinge. Also, da hoffen wir, dass wir das noch ein bisschen optimieren können.
ytunnat
Und die erste, also die Auswertung der ersten Umfrage, die habt ihr ja schon gemacht. Wie ist denn eher die Tendenz, dass eher sehr große Communities mit wirklich vielen Mitgliedern, über 100 oder so, oder gibt es viele kleine? Wie sieht denn da die Landschaft aus?
Monika
Also die Landschaft ist sehr heterogen. Es gibt so ein paar riesengroße Communities wie die Open Preservation Foundation. Es gibt kleine, es gibt sehr spezialisierte, das schränkt natürlich die Möglichkeiten groß zu werden auch so ein bisschen ein.
Ich könnte das jetzt aus der Hand nicht so sagen, wie das Größenordnungsmäßig verteilt ist, aber es gibt wirklich ein recht breites Spektrum davon. Ja.
ytunnat
Und welche Fragen habt ihr noch gestellt, außer zu Größe? Anscheinend ja auch zur Einordnung. Es gibt welche, die allgemein Langzeitarchivierungen machen und dann gibt es auch welche, die sich auf nur bestimmte Aspekte der Langzeitarchivierung beschränken. Könntest du da Beispiele nennen?
Monika
Also Teilaspekte bearbeitet zum Beispiel die DRAG, die Deutsche Rosetta Group. Das ist eine Community, die sich mit diesem System befasst und praktisch so eine Art Interessenverband der Anwender:innen ist, die sich darüber abstimmen können, welche Features sie gerne vom Hersteller geliefert bekommen wollen oder ähnliche Dinge. Es gibt ganz unterschiedliche Motive dafür, weshalb man eine Community hat.
Aber ich könnte noch was dazu sagen, was für Fragen wir gestellt haben. Wir haben die so gewählt, dass sie für Personen und Institutionen, die sich so eine Community suchen, in der sie mitmachen möchten, interessant sein könnten. Und die Fragen reichen dann von formalen Aspekten zu verschiedenen inhaltlichen Aspekten. Formal ist zum Beispiel die Größe der Community, das Sitzland, das Gründungsjahr inhaltlich über die Governance-Struktur bis zum Angebot von Events. Das sind solche Fragen wie, „welche Ziele hat diese Community eigentlich“, „mit welchen Themen befasst sie sich“, „wie finanziert sie sich“, „was für Organe gibt es in der Community“, bis zur Frage, wie die interne und die externe Kommunikation läuft. Also zum Beispiel, wie die Communities soziale Medien nutzen, wie die Reichweite der Community in den sozialen Medien ist und auch die Frage nach Events, die sie anbieten kann. Alles sind Entscheidungskriterien für die Wahl einer Community.
Und am Schluss haben wir dann nochmal danach gefragt, welche Erfolgsfaktoren die Communities eigentlich für sich selbst sehen. Und man sieht, es war ein sehr breites Spektrum an Fragen und es ermöglicht eben, die Ergebnisse in den Profiles so zu sehen, dass man eine Auswahl von Communities, in denen man aktiv werden möchte oder mit denen man kooperiert, gut fundieren kann. Das ist dann so eine Art kleine Registry, diese Profiles.
Aber ich habe auch noch ein paar Beispiele für die Ergebnisse. Die richten sich ja immer zu den Fragen, die man an die Community stellt. Also uns hat es zum Beispiel interessiert, ob die einzelnen Communities eher isoliert, also quasi als Silo gesehen werden müssen oder ob sie sich auch mit anderen Communities vernetzen und offen für das Umfeld sind. Und so war es dann auch. Es gab nur neun von 54 Communities in der ersten Umfrage, die gar nicht mit anderen kooperiert haben. Dann gab es ein breites Mittelfeld, was so einige Kooperationen pflegte. Und es gab zehn Communities, die jeweils mehr als zehn Kooperationen mit anderen Communities unterhalten haben. Also zehn, das waren ja 20 Prozent von den 54.
Dann wissen wir noch, welche Breitenwirkung die Communities nach außen haben, wie viele Kontakte sie über soziale Medien pflegen und generell wie sie sich so mit der Außenwelt kommunizieren und auch da zeigt sich, dass die Communities doch sehr offen sind und eine sehr beeindruckende Außenwirkung entfalten, auch wenn man bedenkt, dass die digitale Langzeitarchivierung ja ein sehr spezielles Thema ist.
Und die geografische Verbreitung hat uns auch interessiert. Das habe ich ja schon gesagt. Also es gibt eine Ballung der Communities in den Industriestaaten und man muss noch mal dahinter gucken, wie das in den anderen Bereichen der Welt ist. Es ist nur die Frage, wie sich das dann organisieren lässt.
ytunnat
Frage ist dann auch, ob die in den sozialen Medien dann engagiert sind. Und wenn ja, in den gleichen Blasen kommt ja auch ein bisschen auf die Sprache an. Wenn die jetzt gar nicht auf Englisch irgendwas machen, dann wird es wahrscheinlich schwierig. Dann hat man gar keine Überschneidungen. Deswegen würde ich auch auf die iPres setzen, glaube ich, um solche Communities zu finden. Vielleicht ist jemand da, der sich damit auskennt. Da sind ja auch oft Leute, die doch nicht unbedingt aus den Ballungszentren nur kommen.
ytunnat
Und es ist ja auch so, ihr habt ja auch so eine Karte gemalt, ne? Also so eine Karte. Habt ihr da auch die Beziehung zwischen den Communities illustriert oder plant, sowas in der Art zu tun?
Monika
Ja, das stimmt. Da kann man sehen, wie sich die Communities über die ganze Welt verteilen.
Monika
Nein, die Beziehung zwischen den Communities haben wir nicht illustriert. Das haben wir nicht, aber das ist eine gute Idee. Wobei wir, das muss ich sagen, nur immer gefragt, wie viele Kooperationen mit anderen Communities die haben. Wir wissen also nicht genau, wer oder wissen es nicht, mit welchen konkret sie dann in Kontakt sind. Das haben wir nicht abgefragt.
ytunnat
Zum Beispiel ist es ja so, dass die DPC relativ lang auch schon mit nestor was zusammen macht. Die Verknüpfung zwischen der OPF und nestor ist wahrscheinlich eher implizit, weil es einige Leute gibt, die bei beiden mitmachen.
Monika
Ja, genau. Das wäre auch noch interessant zu wissen, wie viele Mitglieder in der einen Community auch in anderen aktiv sind. Aber das wird wahrscheinlich sehr schwierig, so etwas zu erheben. Das bekommt man nicht raus. Das ist ohnehin mit der Umfrage und dem Fragebogen ein bisschen schwierig für die, die ihn ausfüllen müssen, weil ich denke, dass man für die Beantwortung bestimmter Fragen auch so eine eigene kleine Statistik braucht und nicht alle Communities haben so etwas. Gerade auch wenn sie sehr informell sind. Dann fehlt auch das Personal, um sich um solche Statistik Anforderungen zu kümmern.
ytunnat
Nee, das kriegt man nicht raus, glaube ich. Da müsste man ja die Mitglieder befragen und ja, da kommt man nicht ran, glaube ich.
ytunnat
Genau, man müsste auch eigentlich ja jemanden haben, der offiziell den Hut aufhat. Und ich frage mich gerade, wer den Hut eigentlich auf hat beim Kölner Stammtisch. Aber da gibt es dann jemanden, der für alle dann antworten konnte. Und da ist es ja dann wahrscheinlich auch eher so, dass es eine implizite Zielgruppe gibt. Wenn man nicht in der Nähe von Köln wohnt, dann fährt man wahrscheinlich eher seltener hin. Also ich hätte jetzt nichts dagegen hinzufahren, aber ich war noch nie da, weil ich eben zu weit weg wohne.
Monika
So klein ist der Stammtisch auch gar nicht.
ytunnat
Nee, da ballt sich ja auch alles. Ich habe auch das Gefühl, dass dort in der Nähe die meisten Langzeitarchivierungs-Aktiven sitzen. Das sind ja mindestens schon mal drei dicke Institutionen, die mir sofort einfallen, die in Köln sind. Ja, das ist krass. Das heißt also, der zweite Durchgang wird jetzt gerade ausgewertet und für den dritten Durchgang sammelt ihr Ideen.
Monika
Ja, wir sammeln Ideen, wie wir die dritte Umfrage besser verteilen können und mehr Leute motivieren können, diesen Fragebogen möglichst komplett auszufüllen.
ytunnat
Und gibt es dieses Jahr noch öffentliche Vorträge von eurer AG irgendwo?
Monika
Also bisher haben wir nichts geplant, aber das wäre durchaus eine Überlegung wert, nochmal zu gucken, wo man das vorstellen könnte. Wir haben ja zwei Umfragen gemacht, haben die auch ein bisschen unterschiedlich angepackt sozusagen. Und es wäre sicherlich interessant, mal bestimmte Ergebnisse der einen und der anderen Umfrage miteinander zu vergleichen und zu gucken, was sich da gewandelt hat.
ytunnat
Ja, ich könnte mir auch vorstellen, dass es die Leute interessant finden würden, vor allem jetzt bei der Ipres vielleicht dann eben nicht dieses Jahr, weil ich glaube die Deadline ist ja demnächst, aber vielleicht dann ja nächstes Jahr oder so.
Monika
Ich denke, wir sollten das auch erst mal ins Netz stellen, bevor wir Vorträge halten. Es kann sich überschneiden, dass man sich vorher schon ein Abstract ausdenkt und das einreicht, aber das sollte schon alles fertig sein, die Profiles und auch die anonyme Auswertung, bevor wir das bewerben.
ytunnat
Ja, stimmt.
ytunnat
Ja, das ist eine sehr schöne Idee, die du da hattest und die ihr da weiterverfolgt. Mir war auch gar nicht klar, dass es so viele Communities gibt und was alles darunter fällt. Ich hätte jetzt auch, wenn man mich gefragt hätte, ohne Vorbereitung wahrscheinlich immer nur die naheliegenden Antworten erstmal gegeben. Aber wenn man länger darüber nachdenkt, dann ist die Welt auch ganz schön vernetzt.
Monika
Ja, auf jeden Fall. Also ich denke schon, dass diese Communities sehr hilfreich sind, um den Transfer von Ergebnissen, die man erzielt hat, in bestimmten Bereichen der digitalen Langzeitarchivierung zu verbreiten und den anderen dann auch damit zu helfen, dass sie ihre eigene digitale Langzeitarchivierung noch optimieren können.
ytunnat
oder einfach nur über gute Ideen. Was mir auch schon passiert ist, dass ich in einem Blogpost von der OPF über ein Problem gesprochen habe, das wir noch nicht gelöst hatten, ich aber gerne automatisiert gelöst hätte und das dann über Twitter auch verbreitet habe und sich dann jemand gemeldet hat, der meinte, ich glaube, ich habe eine Idee, wie ihr das lösen könnt und wir dann im Gespräch auf eine Lösung gekommen sind und das dann vor zwei, drei Jahren umgesetzt haben und das jetzt ein ganz normaler alltäglicher Workflow für uns ist. Und das kam alles nur durch diesen Blogpost. Also offen und öffentlich über seine Probleme zu sprechen, kann einem das Leben erleichtern.
Monika
Man hat ja auch eine vertrauensvolle Umgebung in diesen Communities.
ytunnat
Das stimmt, ja. Das ist sehr angenehm. Habt ihr schon ungefähr eine Idee, wann die Auswertung zu Ende sein wird? Ungefähr wahrscheinlich im Laufe... Ja? Das ist gut, darauf freuen wir uns dann.
Monika
Ich hoffe, dass wir das bis Juni gewuppt haben. Das erscheint im Augenblick realistisch. Was aufwändig ist, ist das Einholen der Profile. Wir stellen erst aus den Umfrageergebnissen diese Seiten zusammen mit den Kennzahlen über bestimmte Communities. Wir schicken denen die aber noch mal zum Gegenlesen und um uns die Erlaubnis einzuholen, die in den Open Access stellen zu dürfen.
Das braucht ein bisschen Zeit, aber wir werden wahrscheinlich die anonymisierten Umfrage-Ergebnisse schon früher bereitstellen können.
ytunnat
Cool. Ja, gibt es etwas, was du noch über die AG Arbeit berichten möchtest?
Monika
Ach, das ist eigentlich ein ganz interessanter Aspekt meiner Arbeitswelt. Es ist interessant. Man guckt über den Tellerrand hinaus. Man lernt was dazu. Man tut was für die Community. Also es ist eine sehr nette Arbeit, die ich sehr schätze. Und auch die Gruppe, mit der wir zusammen sind. Das ist tragfähig.
ytunnat
Cool, das freut mich. Ja, dann vielen Dank für das Gespräch und wir sehen mal dann, wie es weitergeht in ungefähr drei Monaten.
Monika
Vielen Dank.
Communities zur digitalen Langzeitarchivierung: Wo sind sie angesiedelt?
In Frage 6 haben wir gefragt, in welchem Land oder Teil der Welt die Community ansässig ist. Mehrere Gemeinschaften gaben im Texteingabefeld mehr als ein Land an. Wir haben entweder das Land ausgewählt, in dem sie ansässig sind, oder das erste Land, das sie genannt haben.

Interpretation: Fast alle Communities, die in dieser Umfrage vertreten sind, befinden sich in Industrieländern. Entweder konnten wir die Gemeinschaften in anderen Ländern nicht erreichen oder es gibt nur sehr wenige Communities für digitale Langzeitarchivierung in den Entwicklungsländern und weniger entwickelten Ländern. Dies könnte auf einen Mangel an Ressourcen zurückzuführen sein und zeigt, dass es in den meisten Ländern entweder nur wenige Aktivitäten im Bereich der digitalen Langzeitarchivierung gibt oder dass die Akteur:innen in diesem Bereich nicht über die Ressourcen verfügen, um einer Community beizutreten und vom Austausch mit Kolleg:innen in anderen Ländern zu profitieren. Der letztgenannte Aspekt ist vielleicht nicht so wichtig, da die Gemeinschaften immer mehr digital kommunizieren und es eine Fülle von Literatur und Software gibt, die im Internet frei zugänglich ist.
Communities für digitale Langzeitarchivierung: Sind sie Silos oder kooperieren sie miteinander?
In Frage 25 wollten wir wissen, wie viele Kooperationen mit anderen Communities die teilnehmenden Gemeinschaften derzeit haben. Es waren vier Kästchen zum Ankreuzen vorgesehen. Es konnte nur eine Antwort ausgewählt werden.
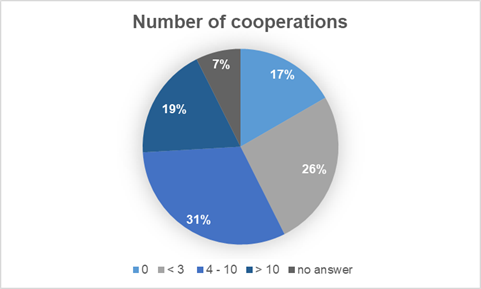
Interpretation: Unsere Daten zeigen deutlich, dass die Communities keine Silos sind und dass sie intensiv mit anderen Gemeinschaften zusammenarbeiten. Nur 17 % arbeiten nicht mit einer anderen Community zusammen, während 19 % mit mehr als zehn anderen Communities kooperieren. Einrichtungen und Personen, die sich mit digitaler Langzeitarchivierung befassen, sind häufig Mitglieder in mehreren Communities, sodass ein breiter Austausch von Ideen, Werkzeugen, Veröffentlichungen und anderen Ergebnissen der gemeinsamen Arbeit stattfindet. Digitale Langzeitarchivierung ist eine Aufgabe, die zu kompliziert ist, um sie allein zu bewältigen, und zwar nicht nur auf individueller Ebene, sondern auch auf der Ebene der Communities. Dies mag der Grund für den intensiven Austausch zwischen den Gemeinschaften sein.
Communities zur digitalen Langzeitarchivierung: Was macht eine Gemeinschaft erfolgreich?
In Frage 40 machten wir uns auf die Suche nach den wichtigsten Faktoren für den Erfolg einer Gemeinschaft. Die Teilnehmer:innen gaben oft mehrere Optionen in die Textfelder ein. Das bedeutet, dass es viele unterschiedliche Antworten auf diese Frage gab. Aus diesem Grund haben wir die in den Texteingabefeldern gegebenen Antworten (soweit möglich) verschiedenen Kategorien zugeordnet und in einer Wortwolke dargestellt. Die Wortwolke enthält sowohl alle kategorisierten Antworten als auch die, für die keine Kategorie gefunden wurde.
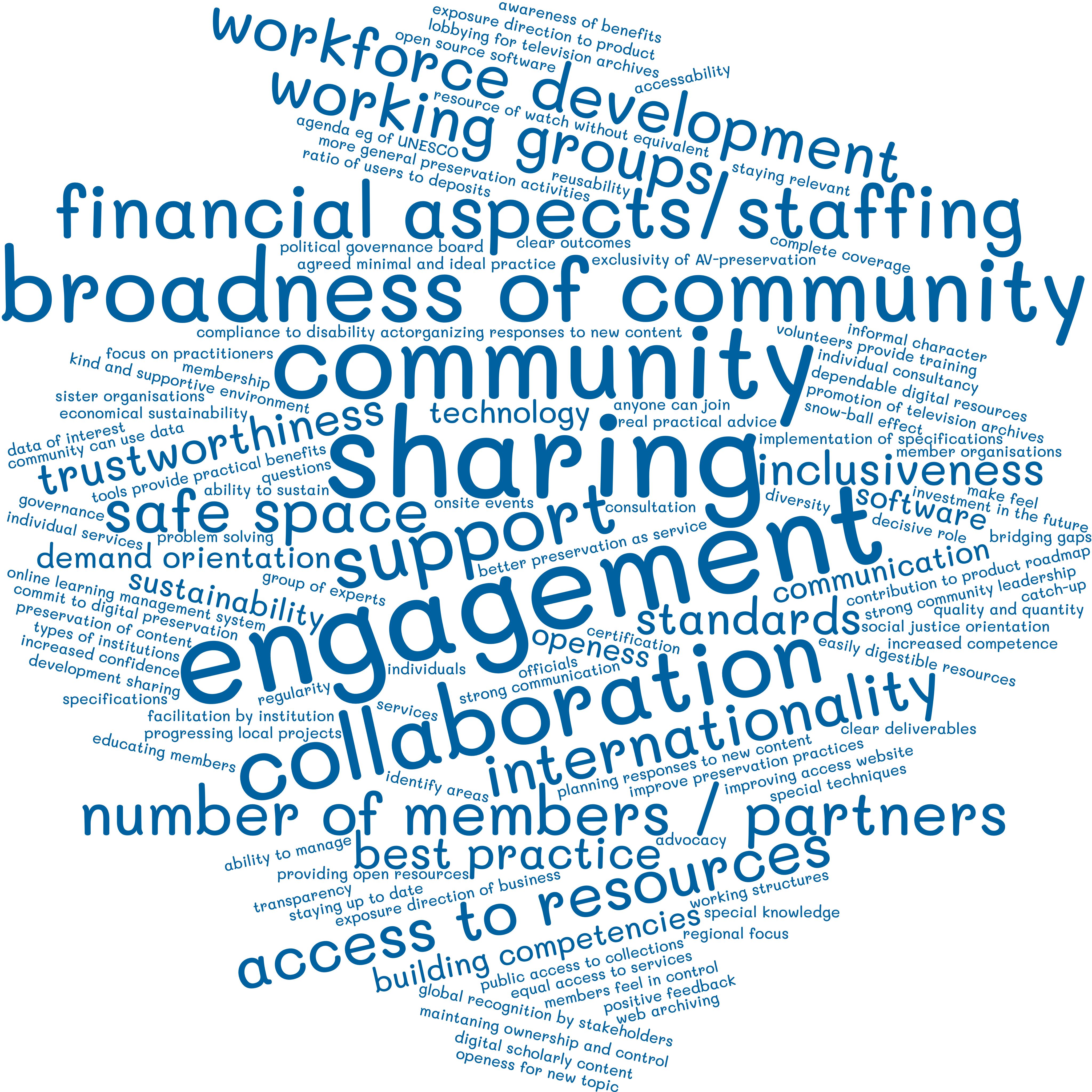
Interpretation: Diese Wortwolke zeigt die wichtigsten Aspekte für den Erfolg einer digitalen Langzeitarchivierungs-Community: Drei Aspekte sind sehr wichtig:
- Kritische Erfolgsfaktoren sind das Engagement, die Zusammenarbeit und die gemeinsame Nutzung von Wissen und Ressourcen.
- Communities unterstützen die Schaffung von Wissen und Technologien für die digitale Langzeitarchivierung.
- Die Bandbreite einer Community ist wichtig, da es bei der digitalen Langzeitarchivierung so viele Details gibt, dass die Vielfalt der Kompetenzen und Perspektiven notwendig ist.
Dieser Text ist eine Übersetzung aus dem Englischen.
Er erschien zuerst bei ZBW Mediatalk unter dem Titel Digitale Langzeitarchivierung: die Vermessung von Netzwerken mit der nestor Community-Survery.
Zugegeben, der Titel ist sehr plakativ, aber gar nicht so wahrheitsfern wie man auf den ersten Blick meinen mag.
Das Paper
Bei der diesjährigen iPRES in Schottland wurde das Paper vorgestellt: OAIS-compliant digital Archiving of Research and Patrimonial Data in DNA (Start auf S. 221). Verfasst wurde das Short Paper von sieben Forschenden aus der Schweiz, von denen die meisten an der Genfer Universität arbeiten. Sie arbeiten zurzeit an einem Projekt , dessen Proof-of-Concept Mitte 2022 fällig war, nach der Deadline des Papers, aber vor dem Vortrag bei der iPRES im September 2022.
Das Thema lautet: Daten speichern auf DNA. Davon hatte ich wohl schon mal gehört, hielt es aber für futuristisch. Bei dem Vortrag hingegen wurde mir klar, dass das praxistauglich ist. Man hat vier Basen (A, C, T und G) und jede Base kann eine Information tragen, beispielsweise eine 00, eine 01, eine 10 oder eine 11 und schon kann man theoretisch so ziemlich alles damit abbilden und das auf erstaunlich wenig Platz.
Codierung im Projekt / Proof of Concept:
| Base | Code |
|---|---|
| A | 00 |
| C | 01 |
| T | 10 |
| G | 11 |
Bei dem Vortrag wurde gesagt, dass dies eine Lösung für jene Daten ist, die selten gebraucht werden, aber lange erhalten werden müssen, aus dem einfachen Grund, dass das Auslesen der Daten eine Weile dauert und Fachpersonal erfordert. Ein erstaunlich hoher Prozentsatz der Daten wird nur selten oder erst nach längerer Zeit wieder benötigt, so dass die Speicherungsmöglichkeit auf DNA bedacht werden sollte.
Unsere Storage-Lösungen fressen unglaublich viel Energie, Tape natürlich weniger als Rechenzentren, aber meistens sind wir auf Strom angewiesen und dies ist angesichts der Klimakatastrophe und der Energiekrise keine Dauerlösung. Wir brauchen andere Lösungen.
DNA kann zwischen 2 und 215 Petabyte pro Gramm (!) an Daten speichern. Im Vergleich: eine handelsübliche externe Festplatte wiegt zwischen 100 und 200 Gramm und kann (Stand November 2022) selten mehr als 2 TB speichern.
| Art Speichermedium | Speichermedium Gewicht | Mögliche Storage-Dichte |
|---|---|---|
| DNA | 2 Gramm | 4.000 TB (oder mehr) |
| externe Festplatte | 200 Gramm | 2 TB |
Die Speicherdichte auf DNA ist hier 200.000 mal so hoch, selbst wenn man (wie in obenstehender Tabelle) von der kleinstgenannten Dichte im Paper ausgeht.
DNA hält bei korrekter Lagerung (keine Energie zur Kühlung etc. notwendig) tausende von Jahren. Aufgrund der hohen Dichte der Daten ist eine Absicherung durch viele Kopien kein Problem.
Drei Vorteile liegen auf der Hand:
- Hohe Datendichte, viele Information passen auf wenige Gramm
- Keine Energie zum Lagern notwendig
- Keine Obsoleszenz (wenn DNA obsolet wird, haben wir ganz andere Problem – keine neue Versionen (DNA Version 2.0 wird es nicht geben)
Diese Idee haben die Forschenden, die das Paper verfasst haben, in OAIS eingebettet, um den gesamten Datenzyklus zu bedenken. Die auf DNA verpackten Daten betreffen natürlich nur das AIP, die Übersetzung der Bits in DNA-Basen erfolgt im Ingestprozess und für die Access-Kopie (DIP) wird wieder zurück übersetzt. Die Architektur ist gebaut auf Standards wie PREMIS, DateCite für die Metadaten, DOI für den persistenten Identifier und OAI-PMH als Schnittstelle. Die DNA Segmente brauchen eine Adresse und es muss klar sein, was darauf gespeichert ist, diese Information muss anderweitig gespeichert sein, damit das Rückübersetzen entfällt.
Die Storage Tubes werden in einem Warenhaus der Archives cantonales vaudoises (ACV) Cantonal Archives of Vaud in der Schweiz gespeichert und die Information (auch die Laborprotokolle, AIP Struktur usw.) werden auf säurefreiem Papier gespeichert. Der langfristige Test beinhaltet, dass die Lesbarkeit nach einem, zwei, fünf, zehn und zwanzig Jahren getestet wird. Pro Vorlage wurden tatsächlich 500.000 Kopien angefertigt. Diese Redundanz kann man sich aufgrund der großen Speicherdichte erlauben.
Diskussion während des Panels
Bei der iPRES wurde das Thema während eines Panels diskutiert. Hier wurde darauf hingewiesen, dass das Beschreiben der DNA noch recht lange dauert, 1 MB pro Sekunde. Bis man ein TB voll hat, ist man mehr als zehn Tage Tag und Nacht beschäftigt. Zahlen für den Access wurden nicht genannt, aber schnell ist das Auslesen auch nicht.
Gefahren für Daten auf DNA sind Oxidation und Hitze, aber man kann sie so aufbewahren, dass diese Gefahren minimiert werden können. Außerdem sind andere Storage-Lösungen auch nicht hitzebeständig und man kann auch keinen LKW drüberfahren lassen und erwarten, dass alles noch in Ordnung ist.
In dem Panel wurden auch offene Fragen thematisiert, beispielsweise wie das File System in der DNA repräsentiert werden. Die DNA Kapseln sollten Barcodes aufgedruckt haben, die die Metadaten dazu liefern.
Es handelt sich hier um eine reine Storage-Lösung, Datei-Obsoleszenz bleibt ein Thema. Es ist denkbar, alle notwendigen Komponenten mitzuspeichern, z. B.Tools zwecks Access und die Datei-Spezifikation.
Nachtrag
Um das alles etwas griffiger zu machen, hat mir Prof. Dr. Dominik Heider freundlicherweise zwei Erklärvideos zu dem Thema weitergeleitet, die das Thema praktisch etwas mehr beleuchten.
Der Datenspeicher der Zukunft? Synthetische DNA!
LOEWE-Schwerpunkt MOSLA-Molekulare Datenspeicher
Glücklicherweise saß ich Mitte September in Schottland in der richtigen Session, um mir den Vortrag zum Paper "Green Goes With Anything: Decreasing Environmental Impact of Digital Libraries at Virginia Tech" von Alex Kinnaman und Alan Munshower anzuhören, das den diesjährigen iPRES Best Paper Award gewonnen hat.
Grund genug, das Paper genauer zu betrachten und die für mich wichtigsten Punkte herauszuarbeiten, da die beiden Autor:innen ein für mich neues Thema in der Digitalen Langzeitarchivierung betrachten, nämlich gute Gründe, etwas NICHT zu tun. Das mag nun plakativ formuliert sein und ist als Prämisse des Papers sicher zu ungenau, doch es stellt die wichtige Aufgabe der Digitalen Langzeitarchivierung in den Kontext des Klimawandels und überlegt eben aktiv, welche Maßnahmen (und wie viele davon) wirklich notwendig sind und welche man reduzieren sollte, um den Co2-Abdruck in Grenzen zu halten. Da der Scope eng ist und die Zahlen genau betrachtet werden, wage ich hier mal eine Zusammenfassung, das vollständige Paper ist zurzeit im Programm zu finden (am Dienstag, 13.09.2022 in dem Slot Environment 1, bald aber auch in den iPRES Proceedings).
Ziel: CO2-Abdruck reduzieren
Alex und Alan haben die Vorgänge an ihrem Arbeitsplatz der Virginia Tech University Library kritisch betrachtet und untersucht, welche Aktivitäten sinnvoll zurückgefahren werden könnten und sollten, um den CO2-Abdruck zu verkleinern. Als Basis haben sie den Artikel Toward environmentally sustainable digital preservation von Pendergrass, Sampson, Walsh und Alagna (2019) genutzt.
Folgende ihrer Workflows/Workflowstationen haben die Autor:innen kritisch untersucht:
- Appraisal
- Digitization
- fixity checking
- storage Choices
Die Balance zwischen dem, was notwendig ist (best practice), und Nachhaltigkeit steht hier im Fokus. Aus aktuellem Anlass (kam in der Session auch aktiv zur Sprache) kann man auch die aktuelle Energiekrise noch erwähnen, die es attraktiv macht, nicht mehr Strom zu verbrauchen als wirklich notwendig.
Die NARA (National Archives and Records Administrations) hat außerdem einen "climate action plan" herausgebracht, der die "climate resilience" stärken möchte und mehr auf cloudbasierte Lösungen setzt (weiter unten hier und später im Paper folgen dazu noch klare Berechnungen).
Der erste Schritt lautet - wenig überraschend:
"[Cultural Heritage Organisations] need to reduce the amount of digital content that they preserve while reducing the resource-intensity of its storage and delivery."
Das steht in krassem Gegensatz zu dem, was in jüngerer Vergangenheit in meiner persönlichen Alltagswirklichkeit gefordert wird: mehr, mehr, mehr. Dieser Paradigmenwechsel wird aber auch hierzulande spürbar, da mehr über Nachhaltigkeit und weniger über Wachstum nachgedacht wird. Auch wir haben begriffen, dass unendliches Wachstum zu Problemen führt. Von eben jenem Paradigmenwechsel ist auch in dem Paper die Rede und es wird auch konkret adressiert, dass es hier möglicherweise einen "acceptable loss" geben könnte, den man aber konkret bedenken und auch benennen sollte, um daran seine praktischen Maßnahmen zur Sicherstellung der Langzeitverfügbarkeit zu orientieren. Denn - und das ist (neben den klaren Berechnungen) - der Kernpunkt des Papers:
"Every decision to acquire, preserve, or replicate a byte of data is, essentially, a commitment to put some amount more carbon into the earth's atmosphere."
Wie später im Paper betont wird, habe man keinesfalls die Absicht, in Kauf zu nehmen, das Klima zu schädigen, vor allem da nicht, wo weniger Maßnahmen zur Erhaltung der Lesbarkeit ausreichen würden.
Welche Maßnahmen sind konkret gemeint?
Erfreulicherweise werden sie dann sehr konkret, welche Maßnahmen sie meinen. Natürlich reden wir hier von digitalen Daten, das bedeutet, jede Aktion kostet Strom. Es gibt ausreichend viele Faktoren, die wir nicht beeinflussen können, wie beispielsweise die Notwendigkeit, Dateien zu migrieren oder auch die Access-Frequenz. Faktoren, die wir in der Tat beeinflussen und steuern können, sind vor allem drei Dinge:
- was wir überhaupt archivieren (Appraisal of Content - wobei ich denke, das muss bei einigen Einrichtungen hierzulande ein wenig anders gesehen werden, die DNB kann beispielsweise nicht aktiv ihren zu archivierenden Bestand einschränken)
- Häufigkeit des Fixity Checks (Checksummen prüfen)
- Anzahl der Kopien, die aufbewahrt werden (in dem Zusammenhang aber auch die Wahl der Storage-Lösung)
Storage-Lösungen, Fixity Check
AWS (Amazon Web Services) verbraucht laut eigenen Angaben 72% weniger CO2, wenn man es mit anderen Datencentern vergleicht (als Quelle wird dies hier angegeben, ich lasse das einfach so stehen, da das nicht der Kernpunkt des Papers ist). In den Berechnungen arbeiten die Autor:innen mit Millijoule (mg), was 0,001 Joule entspricht. Einen Hashwert (Checksumme) für eine Datei zu ermitteln, die 10kb groß ist, verbraucht durchschnittlich 5mj und eine Datei mit der Größe von 1 MB dann 40mj. Hierbei gibt es allerdings noch einen Unterschied, welche Art von Hash ermittelt wird, die Autor:innen zitieren ein Paper, das "found a 29% difference in battery life between choosing the highest and least energy-consuming hash".
Bezüglich der Anzahl der Kopien empfehlen die NDSA Levels of Preservation mindestens drei Kopien, LOCKSS eher 5 bis 7. (In derselben Session sprach auch jemand über LOCKSS und dass die Zahl sieben zurzeit aus ebenjenen Gründen kritisch hinterfragt und überdacht wird.)
Ganz am Anfang steht die Überlegung, was überhaupt archiviert werden sollte, hier ist eine gut durchdachte Collecting Policy sinnvoll. Was gar nicht erst ins Archiv wandert, verbraucht auch keine Energie und umso umsichtiger kann man sich um die Inhalte kümmern, die wirklich wichtig sind (ein Ansatz, der ein wenig an die nestor AG PDA erinnert, wobei diese selbstverständlich einen anderen Fokus und Zielgruppe hat).
Die Inhalte der Virginia Tech sind auf unterschiedliche Cloudlösungen aufgeteilt, die ebenfalls unterschiedlich häufig Fixity Checks durchlaufen, von einmal pro Nacht bis hin zu alle neunzig Tage. Insgesamt verbrauchen ihre Daten knapp 87 kg CO2, und das bei 33,5 TB Gesamtspeicher. Da ich mir darunter so spontan nicht wirklich etwas vorstellen konnte, habe ich ein wenig recherchiert und geschaut. Hier (S. 87, Veröffentlichung im Jahr 2020) wird angegeben, dass ein Desktop-PC mit Monitor im Jahr etwa 87kg CO2 verbraucht, wenn man von einer Nutzungsdauer von zwei Stunden täglich ausgeht. Ich vermute zwar stark, dass dies noch von anderen Faktoren abhängt, aber so kann man sich die Zahl vielleicht besser anschaulich machen.
Fazit und eigene Überlegungen als Diskussionsansatz
Im Fazit geben die Autor:innen noch explizit Tipps zur Reduktion des CO2-Fußabdrucks:
| Art des Tipps im Paper | Eigene Gedanken dazu |
|---|---|
| Include climate considerations in appraisal of digital collection projects | Ist nicht für alle Institutionen möglich / ist nicht immer Aufgabe des LZA-Teams |
| Revisit collection policies and institutional mission | Eine Policy Watch ist immer angebracht, ggf. ist die vor Jahren erstellte Policy nicht mehr klimafreundlich? |
| Decrease redundancy of working files | In meiner Institution würde sich das rein vom Speicher wohl vor allem bei den Materialien aus dem Digitalisierungszentrum lohnen, alle anderen Inhalte fallen im Vergleich nicht sehr ins Gewicht |
| Reduce ongoing fixity checks | Da dies außerhalb meines Aufgabenbereichs liegt, wäre ich interessiert daran, wie oft dieser eigentlich bei uns erfolgt |
| Determine acceptable loss | Ähnliche Gedanken habe ich mir lose zum long tail der Dateiformate gemacht, da klar ist, dass ich nicht gleichermaßen auf alle aufpassen kann |
| Preservation appraisal | Hat auch sehr mit den Preservation Levels / acceptable loss zu tun, kam mir hier ein wenig redundant vor |
| Investigate smaller object sizes | Wäre sicher auch vor allem bei den Materialien aus dem DigiZentrum lohnenswert |
| Sustainability commitment | Sich überhaupt dazu zu bekennen (Policy) wäre dann auch im Rahmen meiner Policy Watch mal angebracht |
| Community trainer | Weitersagen, was man gelernt hat - das mache ich hoffentlich gerade |
Gern möchte ich hier einen Austausch starten, welche Maßnahmen schon getroffen wurden oder ob dieses Thema für Sie ähnlich neu ist wie für mich.
The Situation
There are no conferences.
I know what you are thinking: Of course, there are conferences. Online conferences. Virtual ones, during which I hope the WLAN in my office at home won’t cut me off while somebody says something crucial. Maybe it’s a question of personality, but online conferences are not my cup of tea.
No coffee breaks.
No possibility to ask the person who has just completed a presentation some questions in private.
No tastes.
No smells.
Just listening and - barely – seeing.
And, most importantly: While talking myself, I cannot see your faces. Your faces are hidden. Maybe you are just doing push-ups at your desktop not wanting to be seen. But maybe you are making a face at the things I say, disagreeing. If we were in a conference room, live and in color, I would see your face and could address the problem. As you are invisible for me, I feel like I am just talking to myself.
So, what’s the solution? Skip all the presentations for the time being? Not a solution. There are still people in want of information, including myself. Plus, one of my jobs is Preservation Watch. It’s important. Digital Preservation is moving quickly. I cannot ignore everything and everybody as long as the pandemic lasts – especially as it has been going on for more than 500 days already.
Furthermore, it’s likely that live conferences will be less frequent than they used to be.
I need to know what you are up to. I do not have solutions yet. But I have ideas. Let’s talk about the ideas.
Does Social Media help? Which platforms?

Web Seminars
What’s it about
One or two people doing a presentation about a certain topic. My workmate from ZB MED, Cologne, Dino Wutschka and I have done two this year: One about DROID and one about JHOVE. nestor lists all Web Seminars on its "nestor virtuell" page.
Evaluation
Of course there still is the problem that I cannot see you. Or at least, I cannot see most of you. Up to sixty minutes, 50-100 listeners, some theory at the beginning and practical use afterwards. For sixty minutes, I can stand that. Plus, some of you turn your cameras on. It helps.
Ideas
Powerpoint has always worked fine for me while being live at conferences. I used it for bullet points. Not too fancy. Sufficient, with my temper on a stage. But there is no stage in virtual presentation. Much less temper. I need better Powerpoint skills. And, while we are at it: I need better visual skills in general, also about showing something in a nice and comprehensive way. And nice pictures. Preferably no kitten pictures.
What’s it about
It’s fast. It’s too fast for me. I have always used twitter to ask questions. Worked fine in the past. Nowadays, my questions are too difficult (example here). People always retweet, but tend not to answer any more. Besides, I check my timeline not frequently enough to see interesting content.
Evaluation
It’s still good for advertising blogposts and web seminars and for tweets about ongoing conferences.
Ideas
It seems to be too time-consuming to really get something out of it. I try to use it more often, but I guess I must have more content to do so. Like blogposts. Which brings me to the next point.

Blogging
What’s it about
I have always written blogposts. Usually using the OPF platform. Sometimes the DPC. Now I have the possibility to use nestor, too, which offers the possibility to also blog in my mother tongue.
In the past, I have always spent much time on my blogposts. Usually analysing some hundreds or thousands of files with a handful of tools. Of course that takes a long time. Currently, I have been working on a blogpost with a workmate since last winter. In our spare time. That might be part of the problem: There is no spare time. But there should be. Blogposts are important to share knowledge and more than once I have got ideas back that solve the problems I address in the blogpost. I had some pretty good ideas myself during the last year, hoping to have new ones in 2021.
Evaluation
It works. I need more. I need to put more time into it. It also helps with twitter.
Ideas
Not every blogpost has to be half a paper. I can create short ones, work in progress, just ideas, share what I am working at. Elaboration is always possible afterwards.
Podcasting
What’s it about
Talk to workmates about what they do. Talk to experts about certain topics. Record it. Publish it. nestor has a YouTube channel. Plus, we could distribute it where all the other podcasts are. Like Apple or Spotify.
Evaluation
We have not started yet. There are some technical and organisational challenges, but they can be solved. A workmate of mine has already solved many and I can learn from her. Then we can do it with nestor.
Ideas
It’s another form of gathering information and good/best practice and talking to people and sharing knowledge. It can lead to other ideas. For work. For twitter. For blogposts. Of course it has to be done on top of the normal work. But it should be worth it.
Peer videochat
What’s it about
Meet with peers maybe once a month to talk about a certain topic. Might be certification. Format identification. Format validation. Preservation Planning. PDF format.
Meet for an hour and discuss. Having one person to lead the discussion, preferably an expert on the chosen topic.
Evaluation
Again, we have not started yet. It’s an idea in progress.
Ideas
Maybe once a month for starters. See how it goes. If people want to use it. It will never be as good as real coffee breaks or workshops, but it certainly is better than nothing.
Conclusion
I just had my ten year anniversary on my job. I know what I am doing. But I also know it’s changing. Plus, I need some fresh eyes from time to time. Or refresh my own eyes. Live conferences and talking to you has always done that. I miss that. I need you. Let’s talk.

Am 10. März 2021 zwischen 11 und 12 Uhr fand das erste Webseminar im Rahmen von nestor virtuell statt.
Die Folien wurden mittlerweile auf der nestor Webseite veröffentlicht.
Folgen Sie nestor bei Twitter.
Folgen Sie Dino Wutschka bei Twitter.
Folgen Sie Yvonne Tunnat bei Twitter.
Der offizielle DROID-Userguide ist hier.
Es waren bis zu 112 Teilnehmer:innen anwesend, was im Nachgang zu vielen Fragen und Antworten (größtenteils ebenfalls von den Teilnehmer:innen) geführt hat, die hier gesammelt werden sollen.
Bedienung via Command Line und Einbindung von DROID in Langzeitarchivsysteme
Frage: Haben Sie auch Erfahrungen mit der Command-Line oder der Implementierung von DROID in OAIS-Systemen?
Frage: Gibt es Erfahrungen oder Beispiele für Droid als (interner) Webservice in einer Microservice-Architektur?
Antwort: Ja, für in iPRES-Poster haben Yvonne Tunnat und Micky Lindlar im großen Stil die CLI (und auch Batches) genutzt. DROID ist z. B. in Rosetta eingebunden. In FITS ist es ebenfalls ein Bestandteil. Auch viele andere Archive (wie DIMAG) haben DROID in ihre Langzeitarchivierungssysteme eingebunden. Archivematica hat zurzeit Siegfried eingebunden, ein anderes Identifizierungstool, das ebenfalls die Formatbibliothek PRONOM nutzt.
Als erste Idee würde es reichen, mit SystemD eine Port-Unit zu bauen, da reichen Linux-Bordmittel. Alternativ kann man xinetd nutzen.
Frage: Wo liegen die Unterschiede, wenn ich DROID über GUI oder CLI benutze?
Antwort: Bei DROID sollte Feature Parity zwischen CLI und GUI herrschen. Wie bei CLI-Tools normalerweise der Fall, kann DROID bei der Bedienung via CLI einfacher parametrisiert werden.
Wie gut ist DROID?
Jede Formatidentifizierung kann immer nur eine Heuristik sein, aber gerade für bekannte/verbreitete Formate ist die Heuristik schon ziemlich gut.
Es gibt drei Erkennungsstufen: Extension, Signatur, Container. Ersteres ist unzuverlässig, letztere verlässlicher, Container am verlässlichsten
Neben der Erkennungsrate an sich gibt es natürlich auch eine Rate von "false positiv", also falsche Identifizierungen.
Wobei die Erkennung nur auf die PronomID abbildet. Zu EPUB gibt es z. B. keine PronomIPDs, die die Formatversionen angeben. Also wird das auch nicht erkannt.
Natürlich gibt es auch Dateien, die für DROID (und andere Identifizierungsprogramme) schwer zu erkennen sind. Beim nestor Praktikertag 2017 hatten wir dazu Ange Albertini für die Keynote eingeladen. Von seinen Vorträgen gibt es auch einen bei YouTube.
Die Erkennungsrate lässt sich auch durch die Voreinstellungen beeinflussen, durch die Anzahl an Bytes die analysiert werden. Gerade bei PDF kann das wichtig sein. Z. B. PDF/A wird sonst nicht erkannt.
Performance und Grenzen von DROID
Frage: Gibt es Input-Limits für die Identifizierung von Ordner-Inhalten?
Antwort: Meiner Erfahrung nach gibt es keine Limits, es dauert nur ggf. länger. Bei der Arbeit am iPRES Poster hat Yvonne Tunnat DROID ziemlich strapaziert, indem über 90 Signaturen hintereinander für ein recht großes Sample durchgelaufen sind.
Output von DROID
Frage: Ich überprüfe 20 Dateien. Wie kann ich die Ergebnisse, z.B. die Pronom-ID, z.B. als CSV exportieren? Geht's auch durch die User Interface?
Antwort: Der Export der Ergebnisse von DROID im CSV-Format ist möglich, auch in der GUI.
Kann DROID mehr als nur identifizieren?
Frage: Kann DROID auch zur automatischen Korrektur bei erkannten file extension mismatches genutzt werden?
Antwort: Nein. Das muss stets ein Mensch oder eine erstellte Regel im Nachgang entscheiden.
Kommunikation, Fehlerbehebung durch TNA
Man sollte die Ergebnisse gerade bei neuen oder speziellen Ablieferungen stichprobenartig prüfen und ev. Verbesserungen / Korrekturen an PRONOM weitergeben
Das DROID-Team ist eigentlich recht fix, am Einfachsten via GitHub-Issues.
Zuständig ist David Clipsham
Bei komplexen Anfragen (Beispiel ePub) kann das natürlich länger dauern.
Weitere nützliche Links
Arbeitsweise der Identifikationsmethoden in DROID
https://zenodo.org/record/4593878
DROID Reference Card
https://zenodo.org/record/4593880
Erkennungstiefe bei Identifikations- und Validierungstools
https://zenodo.org/record/4593851
DROID
PRONOM
https://www.nationalarchives.gov.uk/PRONOM/Default.aspx
Willkommen zum neuen nestor-Wiki.
Die Erstellung des Wikis war nur möglich durch die engagierte Arbeit der DNB-Auszubildenden Hanna Mast, Katharina Katzenstein, Peter Estner und Richard Bassenge. Sie haben das Wiki gestaltet und Daten aus dem alten Wiki und aus der Informationsdatenbank übertragen und überprüft. Einen ganz herzlichen Dank dafür!
Ein herzlicher Dank geht auch an die HU, die das alte nestor-Wiki viele Jahre gehostet hat.
Ich hoffe, dass das nestor-Wiki eine produktive Arbeitsumgebung für die nestor-AGs bietet und hilfreiche Ressourcen für die ganze LZA-Community zur Verfügung stellt. Hoffentlich finden sich viele Mitarbeiter, die helfen, die Angebote zu erweitern und aktuell zu halten. Logins für die Mitarbeit gibt es bei der nestor-Geschäftsstelle: VL-nestor@dnb.de.
Das nestor-Wiki ist noch in der Entwurfsphase....