Persistenter Identifikator
Bücher können anhand ihrer ISBN unterschieden werden. Der Begriff persistenter Identifikator ist eine Verallgemeinerung hiervon. Nach DIN 31646 ist ein persistenter Identifikator ein “Name, der eindeutig mit einem Objekt oder mehreren identischen Objekten verknüpft ist” [DIN 31646, Information und Dokumentation - Anforderungen an die langfristige Handhabung persistenter Identifikatoren (Persistent Identifier), Deutsches Institut für Normung, Januar 2013]. Das Adjektiv persistent unterstreicht dabei die Unveränderlichkeit. Der persistente Identifikator und auch das zugehörige Objekt dürfen nicht mehr verändert werden, sobald die Verknüpfung hergestellt ist.
Persistente Identifikatoren eignen sich z.B. für die Referenzierung in Veröffentlichungen, auch für die Referenzierung von Daten. Anstelle der URL wird der persistente Identifikator im Zitat verwendet.

Ein System persistenter Identifikatoren kann als Abbildung im Sinne der Mathematik verstanden werden. Derselbe persistente Identifikator wird unter f stets auf dieselben Daten abgebildet. Mit Hilfe eines Resolverdienstes kann für einen persistenten Identifikator die aktuelle Lokation (URL) des Objektes abgefragt werden. Die URL zeigt gewöhnlich nicht auf die Daten selbst, sondern auf eine Landungsseite (landing page)[1], die die Elemente des Datenzitats (z.B. Autorennamen und Titel), Kern-Metadaten (z.B. Abstract) und einen Zugang zu den Daten (Link, Download-Steuerung) enthält.
URL und Landungsseite dürfen geändert werden. Die URL muss sogar geändert werden, wenn z.B. der Server umzieht und einen neuen Namen im Web bekommt. Die Landungsseite sollte ergänzt werden, wenn zu den publizierten Daten ein Erratum oder ein Nachfolger herauskommt. Dagegen dürfen - wie bereits oben erwähnt - der Identifikator und die Daten nicht verändert werden.
Die Persistenz der Daten muss durch das Datenzentrum sichergestellt werden. Dazu gehört auch die Erhaltung der Lesbarkeit z.B. durch das Umkopieren auf moderne Datenträger und die rechtzeitige Migration in ein nachhaltiges Datenformat. Außerdem müssen URL und Landungsseite aktuell gehalten werden. Diese Aktivitäten, die mit zum Pflichtprogramm der Langzeitarchivierung gehören, sind jedoch nicht Gegenstand dieses Fallbeispiels. Viel mehr soll der Fokus im Folgenden ganz auf die Vergabe persistenter Identifikatoren für Daten gelegt werden.
Kostenarten
Bei manchen Forschungsdatenarchiven ist die Aufnahme der Daten ins Archiv fest mit der Vergabe eines persistenten Identifikators verbunden. In diesem Fall sind die Kosten der Vergabe des persistenten Identifikators Bestandteil der Ingest-Kosten. Sollen die Vergabekosten innerhalb der Ingest-Kosten ermittelt werden, sollten nur die Kosten für die Erzeugung des persistenten Identifikators und den Resolver-Eintrag betrachtet werden, um die Vergabekosten sinnvoll von den anderen Ingest-Kosten abgrenzen zu können.
Anders sieht es aus, wenn sich die Daten schon im Langzeitarchiv befinden. Die Vergabe eines persistenten Identifikators zwecks Veröffentlichung bereits archivierter Forschungsdaten kann aus den folgenden Arbeitsschritten bestehen:
- evtl. Vervollständigung der Metadaten
- evtl. Qualitätssicherung (Daten und Metadaten)
- evtl. Erzeugung bzw. Vervollständigung der Landungsseite
- Erzeugung des persistenten Identifikators
- Resolver-Eintrag
- evtl. Eintrag in einen Metadatenkatalog für die Suche nach persistenten Identifikatoren
Bei der Aufnahme ins Langzeitarchiv wurden bereits Metadaten aufgenommen; für die Datenveröffentlichung mit persistentem Identifikator müssen diese aber oft ergänzt werden. Zu jeder solchen Veröffentlichung gehören ein Titel und die Namen der Autoren. Es kann z.B. aus Sicht der Autoren notwendig sein, Namen zu ergänzen. Statt einer langen Liste von Autorennamen werden manchmal auch die Namen der beteiligten Institutionen eingetragen.
Auch der Titel kann vor der Vergabe des persistenten Identifikators noch verändert oder sogar erstmalig festgelegt werden. Zwar wurden die Daten bei der Aufnahme ins Archiv schon mit einem Titel oder Namen versehen, jedoch handelt es sich dabei nicht selten um Arbeitstitel oder sogar nur Dateinamen, die als solche sehr kurz sind und instituts- oder projektspezifische Bezeichnungen enthalten. Der Titel einer Datenveröffentlichung sollte aber so gewählt sein, dass er zumindest von der gesamten Fachöffentlichkeit verstanden und zugeordnet werden kann. Selbstverständlich sollten Änderungen an Namensliste und Titel nur in Absprache mit den Autoren vorgenommen werden.
Die Qualitätsanforderungen an Daten und Metadaten sind oft höher als bei einer einfachen Archivierung, da die Daten und Metadaten persistent werden. Zwar gibt es in der Regel schon beim Ingest der Daten eine Qualitätskontrolle, aber die mit der Vergabe persistenter Identifikatoren verbundene Unveränderlichkeit von Daten und Metadaten kann eine weitergehende Qualtitätssicherung erforderlich werden lassen. Mindestens die Richtigkeit der im Zuge der Veröffentlichung neu hinzugekommenen Metadaten sollte überprüft werden.
Die in der obigen Liste aufgeführten Tätigkeiten ziehen im Wesentlichen Personalkosten und damit zusammenhängende Kosten für Fortbildung, Dienstreisen und Verwaltung nach sich. Weitere Kosten sind die für Gebäude (Mitarbeiterarbeitsplätze, Nebenräume, Heizung, Strom, Wasser, Telefon- und Netzwerkanbindung, Hausmeister) und Hardware. Falls lizenzpflichtige Software verwendet wird, fallen auch Software-Kosten an.
Im Regelfall ist die Vergabe persistenter Identifikatoren eine Dienstleistung eines schon bestehenden Datenzentrums. Dann werden die Anlagen und Räume dieses Datenzentrums sicherlich mit benutzt werden. Sollen in diesem Fall Gebäude- und Hardware-Kosten bestimmt werden, müsste dies durch Abgrenzung geschehen.
Digital Object Identifier (DOI)
Das DOI-System ist ein Beispiel für ein System persistenter Identifikatoren[2]. DOI werden z.B. zur Referenzierung von digitalen Publikationen und Forschungsdaten benutzt.
Die DOI-Vergabe ist weltweit organisiert. Dachorganisation ist die International DOI Foundation (IDF) [http://www.doi.org/]. Die IDF
- lässt die wichtigste Komponente des DOI-Resolverdienstes von der Corporation for National Research Initiatives (CNRI) betreiben [http://www.crossref.org/01company/16fastfacts.html]
- stellt Policies zur Verfügung
- liefert grundlegende Informationen zum DOI-System
- arbeitet mit Normungsorganisationen zusammen
- bekommt dafür von den Registrierungsagenturen einen Mitgliedsbeitrag
Die IDF registriert nur wenige eigene DOI. Die Registrierung ist viel mehr Sache der Registrierungsagenturen. Die wohl bekannteste ist CrossRef, die DOI für wissenschaftliche Publikationen vergibt [http://www.crossref.org/].
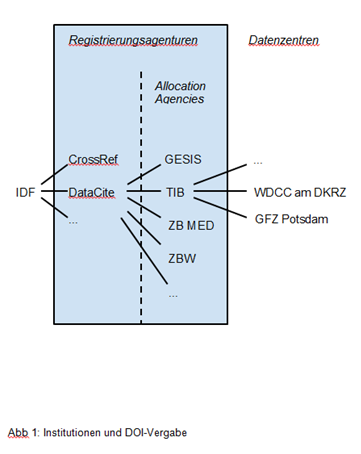
DataCite [https://www.datacite.org/] ist die weltweite DOI-Registrierungsagentur für Forschungsdaten und ist Mitglied der IDF. Neben der Lieferung von DOI für Forschungsdaten bietet DataCite noch weitere Dienste an, beispielsweise
- DataCite Metadata Store
- DataCite Metadata Search
- Statistik-Dienst
Mitglieder von DataCite sind nationale Institutionen, die Allocation Agencies, die sich in DataCite zum Zwecke der Registrierung von Forschungsdaten zusammengeschlossen haben. DataCite-Vollmitglieder zahlen einen jährlichen Mitgliedsbeitrag von zurzeit 8.500€. Die vier deutschen DataCite-Mitglieder waren zur Zeit der Erstellung dieses Fallbeispiels
- GESIS (Leibnitz-Institut für Sozialwissenschaften)
- TIB (Technische Informationsbibliothek)
- ZB MED (Deutsche Zentralbibliothek für Medizin)
- ZBW (Leibnitz-Informationszentrum Wirtschaft)
Datenzentren, die die DOI-Vergabe für Forschungsdaten anbieten wollen, schließen einen Vertrag mit einer dieser Allocation Agencies. Eine eigene DataCite-Mitgliedschaft ist nicht erforderlich. Die Datenzentren halten Kontakt zu den Forschern, die ihre Daten veröffentlichen wollen, und liefern die für die Veröffentlichung erforderlichen Metadaten an DataCite. Die Metadaten müssen im DataCite-Metadatenschema [http://schema.datacite.org/] vorliegen. Die Vereinheitlichung erleichtert die Speicherung und die Suche in den Metadaten.
Beispiel für ein Datenzentrum: Deutsches Klimarechenzentrum (DKRZ)
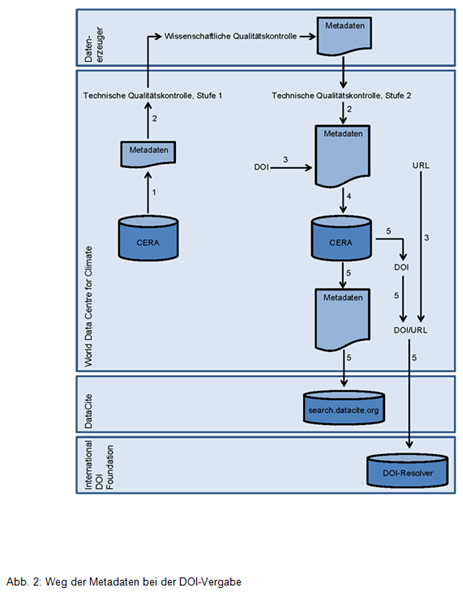
Den Weg der Metadaten im Publikationsprozess zeigt Abb. 2. Die DOI-Vergabe setzt voraus, dass die Daten bereits am WDCC archiviert sind. Die für die Archivierung erforderlichen Schritte sind in Abb. 2 nicht eingezeichnet. Ingest, Langzeitspeicherung (Bitstream-Preservation + Datenpflege) und DOI-Vergabe sind drei unterschiedliche Hauptprozesse am WDCC, die getrennt voneinander abgerechnet werden. Beim Ingest wurde auch bereits ein Satz Metadaten eingefüllt. Diese sind in CERA, der Metadatenbank des WDCC, gespeichert.
Zu Beginn wird der Publikationsprozesses mit dem Principal Investigator abgestimmt. Ein WDCC-Mitarbeiter erfragt,
- wer Kontaktperson ist
- welche Daten dazugehören und wie diese gegliedert sind
- ob die Daten bereits archiviert sind (Falls dieser letzte Punkt nicht erfüllt ist, ist ein Ingest erforderlich, der gesondert abgerechnet wird.)
Der zweite Teilprozess (Schritt 2) ist umfangreich, denn dem WDCC obliegt die technische Qualitätskontrolle der Daten und Metadaten sowie die Ergänzung der Metadaten, z.B. um Qualitätsinformationen. Die wissenschaftliche Qualitätskontrolle der Daten ist hingegen Sache des Auftraggebers. Zur technischen Qualitätskontrolle gehören Tests, ob
- die Zahl der Datensätze korrekt und ≠ 0 ist
- die Größe jedes Datensatzes ≠ 0 ist
- das Datenvolumen korrekt ist
- das Datenformat valide ist
- die in den Metadaten angegebenen Zeiten in den Daten gefunden werden können (Start- und Stoppdatum, Zeitschritt)
- Variablenbeschreibungen und Daten konsistent sind
Die letzten beiden Tests sind personalintensiv[4]. Bei sehr umfangreichen und komplexen Daten wird ausgehandelt, ob das WDCC die beiden letzten Tests tatsächlich alle durchführen oder aus Zeitgründen nur einen Teil der Daten prüfen soll. Welche Tests ausgeführt werden, wird dokumentiert.
Die mit der Qualitätskontrolle befassten Mitarbeiter teilen die technische Qualitätskontrolle oft in zwei Stufen auf. In der ersten Stufe werden nur die Tests durchgeführt, die vor der wissenschaftlichen Qualitätskontrolle liegen müssen. Die zweite Stufe enthält die aufwändigeren Tests und wird einfach weggelassen, falls die Datenproduzenten nach der wissenschaftlichen Qualitätskontrolle doch keinen DOI mehr wünschen. Das hat am WDCC zu einer spürbaren Verringerung des Aufwands geführt.
Falls Unstimmigkeiten gefunden werden und eine Korrektur der Metadaten allein nicht ausreicht, hat der Datenerzeuger die Wahl zwischen drei Möglichkeiten des weiteren Vorgehens: Der Datenerzeuger kann die Unstimmigkeiten in den Metadaten dokumentieren, ein Erratum herausgeben oder die Daten neu erzeugen. Letzteres bedeutet eine erneute Archivierung, zu der auch eine eigene, von der DOI-Vergabe getrennte Qualitätskontrolle gehört.
Der hintere Teil des DOI-Namens wird durch das WDCC festgelegt. Als URL wird die der Landungsseite genommen, die zu den Daten gehört (Schritt 3).
Die geänderten Metadaten werden in CERA eingetragen (Schritt 4).
Die Konvertierung der Metadaten ins DataCite-Metadatenschema erfolgt in Schritt 5 automatisch mit Hilfe von DB-Views und Skripten. Die Metadaten liegen nun als XML-Datei vor und werden über den Metadata-Store-Webservice bei DataCite registriert. Dieser Schritt ist zugleich letzte Kontrolle. Der Metadata-Store-Webservice erledigt auch die Registrierung des DOI/URL-Paares.
Beim abschließenden Eintrag in Atarrabi wird von Atarrabi automatisch eine E-Mail an die Kontaktperson verschickt. Außerdem schreibt ein WDCC-Mitarbeiter eine persönliche E-Mail.
Die Kosten für die DOI-Vergabe müssen im Prinzip von denjenigen getragen werden, die sie in Auftrag gegeben haben. Die DOI-Nutzung in Zitaten ist selbstverständlich kostenfrei. Bisher wurden DOI für Kunden vergeben, die zugleich Nutzer von Compute-Dienstleistungen des DKRZ sind. In diesem Fall werden die Kosten mit den bewilligten Kontingenten verrechnet, und die DOI-Vergabe ist de facto kostenlos. In den letzten Jahren sind die Datendienste des DKRZ aber auch für andere Kunden interessant geworden, die nicht Nutzer des Großrechners sind, aber dennoch Klimadaten langfristig archivieren wollen. Aus diesem Grund wurde am WDCC ein Preismodell entwickelt.
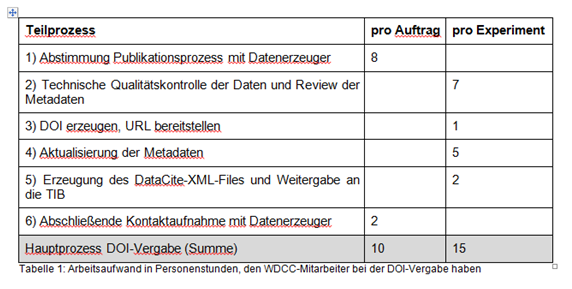
Die Grundlage für Kostenvoranschläge des WDCC ist eine Teilkostenrechnung [Luthardt, H., Datenspeicherung und -verteilung von Projektdaten am DKRZ (≥ 10 Jahre), https://www.dkrz.de/daten-en/data-services/long_term_archiving/LZA_Kostenabschaetzung_generell_v02.pdf/at_download/file]. Nur der Personalaufwand nach Tabelle 1 geht in den Preis ein. Andere Kosten, wie z.B. Fortbildungs- und Gebäudekosten, bleiben bis auf weiteres unberücksichtigt. Für die Kalkulation wurde bisher ein Arbeitgeberbrutto von 5000 €/Monat und eine Arbeitszeit von 160 Stunden pro Monat angesetzt. Das entspricht Personalkosten von 31,25 € pro Arbeitsstunde. Werden diese mit dem in Tabelle 1 für den Hauptprozess DOI-Vergabe ermittelten Arbeitsaufwand multipliziert, erhält man eine affine Funktion, mit der sich Kunden leicht selbst einen Kostenvoranschlag berechnen können.
P = 312,50 € + 468,75 € ∙ n
Die Funktion setzt sich - wie es sich für eine affine Funktion gehört - aus einem konstanten Sockel und einem linearen Summanden zusammen. Im konstanten Sockel steckt der Aufwand für die Arbeitsschritte, die nur einmal pro Auftrag anfallen. Der lineare Summand beschreibt die Abhängigkeit von der Zahl n der Experimente. Alle Preise sind netto, d.h. ohne Mehrwertsteuer.
Die Kunden, die sich DOI für ihre Daten haben geben lassen, waren bisher zugleich Nutzer des Großrechners des DKRZ und konnten die Kosten mit bewilligten Kontingenten verrechnen. Daher ist bisher noch keine Rechnung für die DOI-Vergabe herausgegangen. Der genaue Endpreis nach erfolgter DOI-Vergabe hinge vom tatsächlichen Aufwand, d.h. von den Daten und Metadaten, ab und wäre Verhandlungssache. Obige Preisformel gibt auch den Kostenvoranschlag nicht ganz exakt wieder, da in einen vom WDCC herausgegebenen Kostenvoranschlag noch Rundungsschritte eingehen würden.
Beispiel für eine Allocation Agency: TIB
Allocation Agency des WDCC ist die Technische Informationsbibliothek in Hannover. Die TIB schließt mit Datenzentren mit Schwerpunkt Naturwissenschaften und Technik Verträge über die Aufgabenverteilung bei der DOI-Vergabe ab. Im Vertrag garantiert die TIB den Zugang zu folgenden Leistungen [Vertrag über die Bereitstellung von Digital Object Identifiers (DOI), Mustervertrag der TIB, Stand 24.9.2012]:
- Bereitstellung und Registrierung von DOI
- Metadaten-Verwaltungsdienst, der es dem Datenzentrum ermöglicht, die Metadaten an DataCite zu übermitteln und mit einem DOI zu verknüpfen
- Speicherung der Metadaten: Diese werden über ein Online-Portal öffentlich zugänglich gemacht
Datenzentrum und TIB tragen die innerhalb ihres Tätigkeitsbereiches anfallenden Kosten selbst. Akademische Datenzentren in Deutschland zahlen keine Gebühren für die DOI-Registrierung durch die TIB. Andere Datenzentren - nicht-akademische und solche mit Hauptgeschäftssitz außerhalb der Bundesrepublik Deutschland - zahlen 150 € Jahresgebühr [Anlage 1 zum Vertrag über die Bereitstellung von DOI, Mustervertrag der TIB, Stand 24.9.2012]. Darin sind jährlich 500 DOI-Namen und die Speicherung der zugehörigen Metadaten enthalten.
Für die Registrierung weiterer DOI gilt die folgende Preisstaffel:

Zu den Pflichten des Datenzentrums gehört vor allem die Lieferung von Metadaten zu einem DOI, die dem DataCite-Metadatenschema entsprechen.
[1] Das ist zumindest best practice.
[2] Eine Übersicht zu Identifikator-Systemen kann im nestor-Handbuch [K. Schroeder, Persistent Identifier (PI) – ein Überblick, in H. Neuroth, A. Oßwald, R. Scheffel, S. Strathmann, & K. Huth (Hrsg.), nestor Handbuch: Eine kleine Enzyklopädie der digitalen Langzeitarchivierung. Göttingen, Niedersachsen: http://www.nestor.sub.uni-goettingen.de/handbuch/nestor-handbuch_23.pdf, neben der Online Version 2.3 ist die Printversion 2.0 beim Verlag Werner Hülsbusch, Boizenburg erschienen] gefunden werden.