Ablauf der Kandidatenbearbeitung
Beim Import von Datensätzen in die GND per Match&Merge werden in vielen Fällen auch Kandidaten markiert, d.h. ein gelieferter Datensatz, bei dem nach der M&-Konfiguration nicht sicher ist, ob er wirklich eine Dublette zu einem bereits vorhandenen GND-Datensatz ist, wird als ein neuer Datensatz eingespielt und im Feld 169 mit der möglichen Dublette verknüpft:
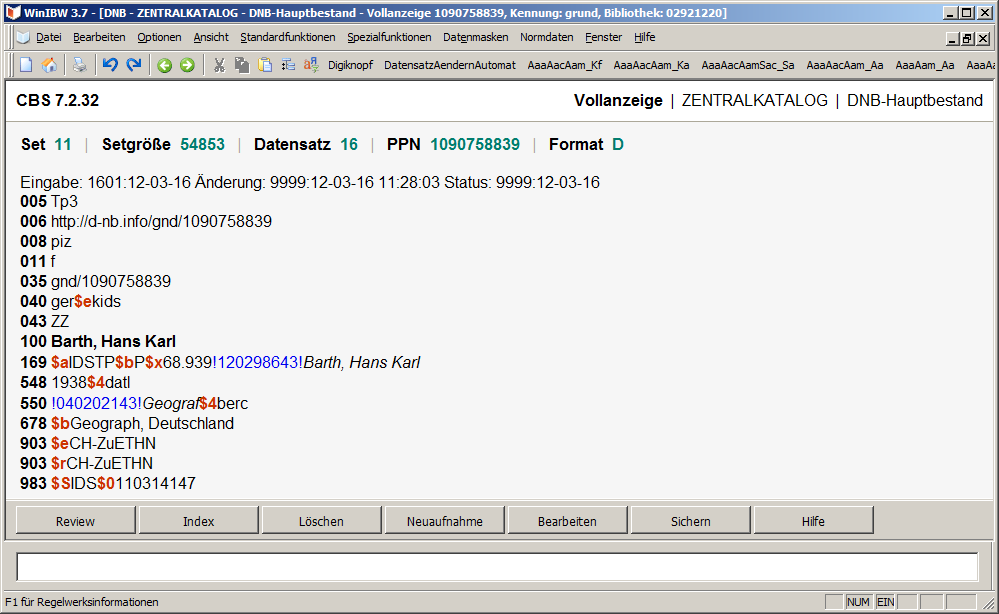
Trifft man auf einen solchen Fall, ist eine intellektuelle Prüfung, ob es sich wirklich um eine Dublette handelt, mithilfe der Entdoppelungs-Funktion sehr einfach: Mit dem Befehl ent über die Komandozeile erhält man eine Ansicht beider Datensätze nebeneinander, wobei identische Inhalte grün markiert sind, abweichende hingegen rot:
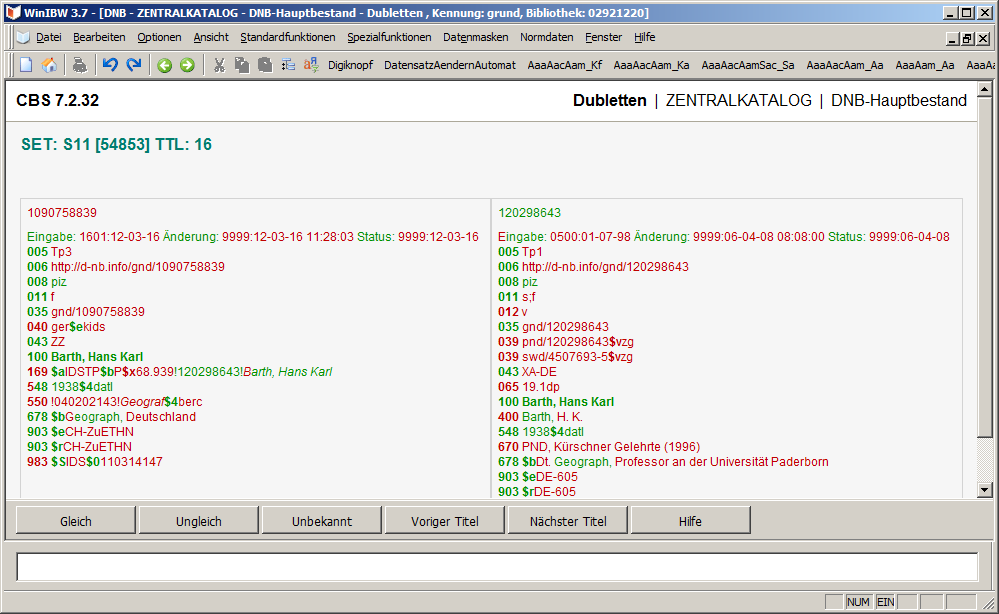
Ist man jetzt der Meinung, es handelt sich wirklich um eine Dublette, klickt man auf den Button "Gleich", falls es keine Dublette ist, auf "Ungleich". Ist man unsicher, klickt man auf "Unbekannt" oder kommt mit "Escape" zurück zur normalen Anzeige.
"Gleich" bewirkt, dass
$bP("P" wie "possible") durch$bMersetzt wird ("M" wie "Match")- in einem nächtlichen Lauf eine Umlenkmarkierung zur Dublette eingetragen wird (
010 u,682 !...!), und dabei - aus dem Verlierersatz sämtliche Informationen in den Gewinnersatz übernommen werden ("Merge"), die auch beim Import per Match&Merge übernommen worden wären, wäre das Paar dort bereits 100%ig als Dublette erkannt worden. Dies sind grob gesagt alle 4XX, 5XX und 6XX-Felder sowie ein abweichendes 1XX als 4XX. (Nähere Informationen zur Merge-Konfiguration sind unter Vorgaben für Match&Merge zu finden). Diese Felder müssen also im Gegensatz zu einer normalen Umlenkung nicht mehr händisch übernommen werden. Im wöchentlich stattfindenden Umlenkverfahren werden dann zusätzlich noch die Statusfelder übernommen, die auch sonst beim Umlenken übernommen werden (011, 012, etc., für nähere Informationen hierzu s. den Erfassungsleitfaden für das Feld 682)
- um die Online-Schnittstellen zu den GND-Partner nicht zu sehr zu belasten, werden pro Kontingent zur Zeit pro Nacht nur 200 Datensätze abgearbeitet. Wenn an einem Tag mehr als 250 Datensätze nach dem oben beschriebenen Muster intellektuell bearbeitet wurden, würde der Rest eine Nacht später vom Job bearbeitet werden.
"Ungleich" bewirkt, dass
$bP("P" wie "possible") durch$bNersetzt wird ("N" wie "Nomatch")- das Feld 169 in einem nächtlichen Lauf aus dem Datensatz entfernt wird.
"Unbekannt" bewirkt, dass
$bP("P" wie "possible") durch$bUersetzt wird ("U" wie "Unknown"). Dies kann für spezielle Selektionen genutzt werden, um sich später beispielsweise bereits erkannte Problemfälle anzeigen zu lassen.
Wenn man sich in einer Liste von Kandidaten befindet, beispielsweise nach einer Selektion wie unten beschrieben, wird nach dem Klick auf einen der "gleich/ungleich/unbekannt"-Buttons automatisch das nächste Paar der Ergebnisliste angezeigt.
Selektion von Kandidaten
Will man Kandidaten gezielt abarbeiten, kann man sie mit folgender Suchanfrage selektieren:
f mm <Kontingent> <Status> <Matchwert>?
- "Kontingent" (169 $a): Dies ist die Bezeichnung, die beim Einspielen für bestimmte Kontingente vergeben wurde, um sie später selektieren zu können. Zur Zeit gibt es folgende Kontingente:
- "ADB": Einspielungen von Verlagsdatensätzen des MVB/Adressbuch des Deutschen Buchhandels (Körperschaften)
- "DBSMG", "DBSMP": Einspielungen aus dem Deutschen Buch- und Schriftmuseum (DBSM); G = Körperschaften, P = Personen
- IDSTB, IDSTF, IDSTFVIF, IDSTG, IDSTP, IDSTU: Einspielungen aus dem Informationsverbund Deutschschweiz (IDS); "TB" = Körperschaften, "TF" = Kongresse einzeln, "TFVIF" = Kongressfolgen, TG = Geografika, TP = Personen, TU = Werke
- NBTB, NBTF, NBTP: Einspielungen aus der Schweizerischen Nationalbibliothek (NB); "TB" = Körperschaften, "TF" = Kongresse einzeln, TP = Personen
- "Status" (169 $b): Welchen Status hat das Kandidatenpaar?
- "P": possible, möglicher Match (Standardstatus nach der Einspielung der Kandidaten)
- "N": nomatch, kein Match (nach intellektueller Bearbeitung)
- "M": Match (nach intellektueller Bearbeitung)
- "U": unknown, unbekannt (nach intellektueller Bearbeitung, kann für spätere Selektionen genutzt werden, um dann die Problemfälle abzuarbeiten)
- "Matchwert" (169 $x): Der Matchwert, dem das Kandidatenpaar von Match&Merge beim Einspielen vergeben wurde. Dies kann man nutzen, um sich erst die Paare mit einem besonders hohen Matchwert anzeigen zu lassen. Man kann den Matchwert in der Suchanfrage aber auch einfach weglassen. Die Matchwerte, die für Kandidaten vergeben wurden, sind auf Vorgaben für Match&Merge dokumentiert. (Matchwerte werden in der WinIBW mit 100 multipliziert dargestellt, d.h. bekommt ein Paar bei Match&Merge den Matchwert 0.75000, wird dies in der WinIBW als 75.000 angezeigt!)
Beispiele (Groß- und Kleinschreibung ist bei Suchanfragen nicht distinktiv):
f mm idstp p 7? (zeige mir alle noch nicht bearbeiteten Kandidatenpaare des IDS-Imports Personen an, die einen Matchwert 0.7xxxx erhalten haben (in der WinIBW als 7x.xxx dargestellt))f mm idstb p? (zeige mir alle noch nicht bearbeiteten Kandidatenpaare des IDS-Imports Körperschaften an)f mm adb u? (zeige mir die intellektuell als unklar markierten Kandidatenpaare des ADB-Imports an)
Überblick
Inhalte